

Perform area estimation analysis with SEPAL-CEO#
Complete area estimation for land use/land cover and two-date change detection classifications
Note
The SEPAL team would like to thank SIG-GIS for this documentation material (SIG-GIS refers to the Spatial Informatics Group - Geographic Information System).
Important
To follow this tutorial, you need to register to:
SEPAL
Google Earth Engine (GEE)
Collect Earth Online (CEO)
Introduction#
In this article, you will learn how to perform area estimation for land use/land cover and two-date change detection classifications. We will use sample-based approaches to area estimation. This approach is preferred over pixel-counting methods because all maps have errors (e.g. maps derived from land cover/land use classifications may have errors due to pixel mixing or noise in the input data). Using pixel-counting methods will produce biased estimates of area; you cannot tell whether these are overestimates or underestimates. Sample-based approaches create unbiased estimates of area and the error associated with your map.
The goal of this article is to teach you how to perform these tasks so that you can conduct your own area estimation for land use/land cover or change detection classifications.
In this article, you will find four modules covering methods and one module covering the documentation needed for replicating these methods. The modules are as follows:
In Module 1, you will learn how to generate mosaics based on satellite imagery in SEPAL. You will learn how to build these mosaics by selecting different data sources and images based on dates and cloud cover.
In Module 2, you will learn how to perform a land use/land cover image classification using random forest methods. You will learn how to define your land uses and land covers, collect training data, and run your model.
In Module 3, you will learn how to perform image change detection. Building on skills from Module 1 and Module 2, you will define what change looks like, collect training data, and run your model. You will also learn about different tools used to perform time-series analysis.
In Module 4, you will learn how to calculate a sample-based estimate of area and error. You will learn how to use stratified random sampling and verification image analysis to calculate area and error estimates based on the classification you create in Module 2. You will also learn about some key documentation steps in preparation for Module 5.
In Module 5, you will learn about documenting and archiving your area estimation project. The information in this step is required for your project to be replicated by yourself or your colleagues in the future (either for additional areas or points in time).
These exercises include step-by-step directions and are built to facilitate learning through reading and practice. This article will be accompanied by short videos, which will visually illustrate the steps described in the text.
![digraph process {
mosaic [label="Mosaic image creation", href="#mosaic-generation-landsat-sentinel-2", shape=box];
classif [label="Image classification", href="#image-classification", shape=box];
change [label="Two-date change detection", href="#image-change-detection", shape=box];
sample [label="Sample-based area and error", href="#sample-based-estimation-of-area-and-accuracy", shape=box];
doc [label="Documentation", href="#documentation-and-archiving", shape=box];
mosaic -> classif;
mosaic -> change;
classif -> sample;
change -> sample;
sample -> doc;
}](../_images/graphviz-822e05f396072876b47588fdbbf3a23d3e0728b8.png)
Required tools#
SEPAL#
The primary tool needed to complete this tutorial is the System for Earth Observation Data Access, Processing and Analysis for Land Monitoring (SEPAL) – a web-based cloud computing platform that enables users to create image composites, process images, download files, create stratified sampling designs and more (all from your browser). Part of the Open Foris suite of tools, SEPAL was designed by the Food and Agricultural Organization of the United Nations (FAO) to aid in remote sensing applications in developing countries. Geoprocessing is possible via Jupyter, JavaScript, R, R Shiny apps, and RStudio; the platform also integrates GEE and CEO.
SEPAL provides a platform for users to access satellite imagery (Landsat and Sentinel-2) and perform change detection and land cover classifications using a set of easy-to-use tools. SEPAL was designed to be used in developing countries where internet access is limited and computers are often outdated and inefficient for processing satellite imagery. It achieves this by utilizing a cloud-based supercomputer, which enables users to process, store and interpret large amounts of data. (There are many advanced functions available in SEPAL, which we will not cover in this article.)
CEO#
CEO is a free, open-source image viewing and interpretation tool, suitable for projects requiring information about land cover and/or land use, enabling simultaneous visual interpretations of satellite imagery, providing global coverage from MapBox and Bing Maps, a variety of satellite data sources from GEE, and the ability to connect to your own Web Map Service (WMS) or Web Map Tile Service (WMTS). The full functionality is implemented online; no desktop installation is necessary. CEO allows institutions to create projects and enables their teams to collect spatial data using remote sensing imagery. Use cases include historical and near real-time interpretation of satellite imagery and data collection for land cover/land use model validation.
GEE#
GEE combines a multi-petabyte catalog of satellite imagery and geospatial datasets with planetary-scale analysis capabilities and makes it available for scientists, researchers and developers to detect changes, map trends and quantify differences on the Earth’s surface. The code portion of GEE (called Code editor) is a web-based IDE for the GEE JavaScript API; its features are designed to make developing complex geospatial workflows fast and easy.
The Code editor has the following elements:
JavaScript code editor;
a map display for visualizing geospatial datasets;
an API reference documentation (Docs tab);
Git-based script manager (Scripts tab);
Console output (Console tab);
Task manager (Tasks tab) to handle long-running queries;
Interactive map query (Inspector tab);
search of the data archive or saved scripts; and
geometry drawing tools.
Tip
For more information, see:
Project planning#
Project planning and methods documentation play a key role in any remote sensing analysis project. While we use example projects in this article, you may use these techniques for your own projects in the future.
We encourage you to think about the following items to ensure that your resulting products will be relevant and that your chosen methods are well documented and transparent:
Descriptions and objectives of the project (issues and information needs).
Are you trying to conform to an Intergovernmental Panel on Climate Change (IPCC) Tier?
Descriptions of the end user product (data, information, monitoring system or map that will be created by the project).
What type of information do you need (e.g. map, inventory, change product)?
Do you need to know where different land cover types exist or do you just need an inventory of how much there is?
How will success be defined for this project? Do you require specific accuracy or a certain level of detail in the final map product?
Description of the project area/extent (e.g. national, subnational, specific forest).
Description of the features/classes to be modeled or mapped.
Do you have a national definition of “forest”?
Are you aware of the IPCC guidelines for the recommended land-use classes and how they will relate to mapping land cover?
Do you have key categories that will drive different analysis techniques?
Considerations for measuring, reporting and verifying your data.
Do you have a strategy? Do you know what is required? Do you know where to get the required information? Looking ahead, are you on the right path? Who are the decision makers that will inform these strategies?
What field data will be required for classification and accuracy assessment?
Do you have an existing National Forest Monitoring System (NFMS) in place?
Will you supplement your remote sensing project with existing data (local data on forest type, management intent, records of natural disturbance, etc.)?
Partnerships (vendors, agencies, bureaus, etc.).
Mosaic generation (Landsat & Sentinel 2)#
SEPAL provides a robust interface for generating Landsat and Sentinel 2 mosaics. Mosaic creation is the first step for the image classification and two-date change detection processes covered in Module 2 and Module 3, respectively. These mosaics can be downloaded locally or to your Google Drive account.
In this tutorial, you will create a Landsat mosaic for the Mai Ndombe region of the Democratic Republic of the Congo, where REDD+ projects are currently underway.
Note
Objectives
learn how to create an image mosaic;
familiarize yourself with a variety of options for selecting dates, sensors, mosaicking and download options; and
create a cloud-free mosaic for 2016.
Note
Prerequisites
SEPAL account registration
Create a Landsat mosaic#
If SEPAL is not already open, open your browser and go to: https://sepal.io/ . Log in to your SEPAL account.
Select the Processing tab.
Then, select Optical Mosaic.
When the Optical mosaic tab opens, you will see an Area of interest (AOI) window in the lower-right corner of your screen.
There are three ways to choose your AOI. Open the menu by selecting the carrot on the right side of the window label.
Select Country/Province (the default)
Select from EE table
Draw a polygon
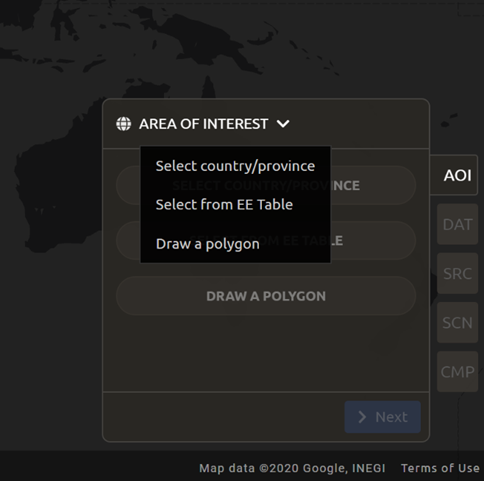
We will use the Select a country/province option.
In the list of countries, scroll down until you see the available options for Congo, Dem Republic of (note: There is also the Republic of Congo, which is not what we’re looking for).
Note
Under Province/Area, notice that there are many different options.
Select Mai-Ndombe.
Tip
Optional: You can add a Buffer to your mosaic. This will include an area around the province of the specified size in your mosaic.
Select Next.
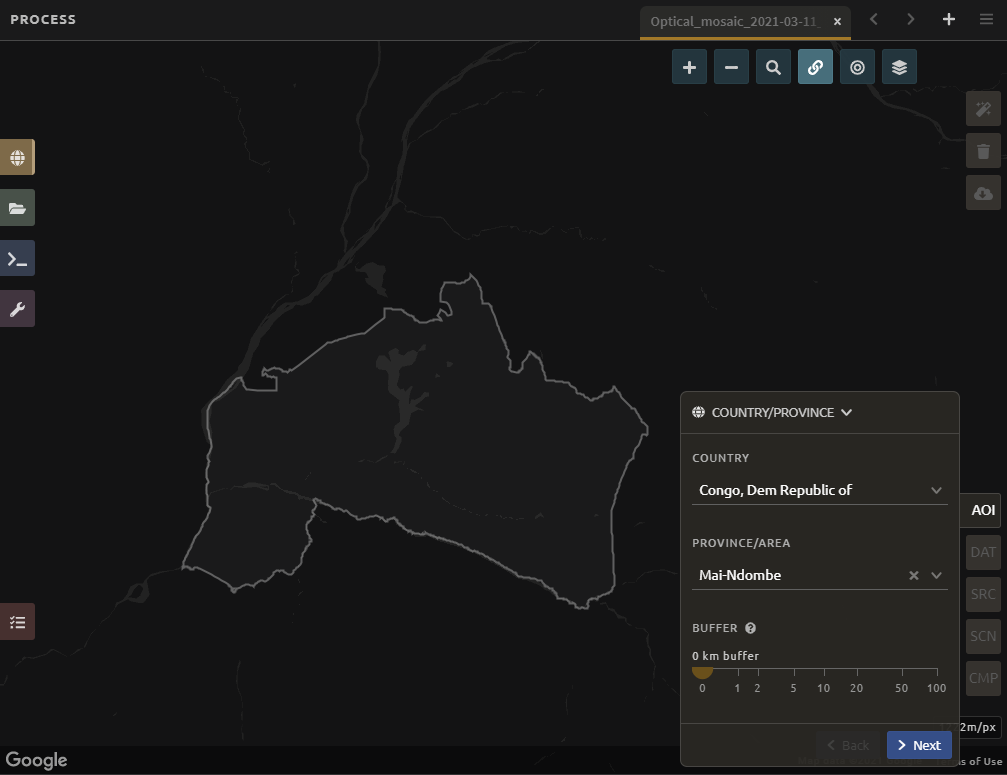
In the Date menu, you can choose the Year you are interested in or select More.
This interface allows you to refine the dates or seasons you are interested in.
You can select a
target date(the date in which pixels in the mosaic should ideally come from), as well as adjust the start- and end-date flags.You can also include additional seasons from the past or the future by adjusting the
Past SeasonsandFuture Seasonsslider. This will include additional years’ data of the same dates specified (if you’re interested in August 2015, including one future season will also include data from August 2016). (This is useful if you’re interested in a specific time of year, but there is significant cloud cover.)For this exercise, let’s create imagery for the dry season of 2019.
Select July 1 of 2019 as your target date (2019-07-01), and move your date flags to May 1-September 30.
Select
Apply.
Now select the Data Sources (SRC) you’d like. Here, select the Landsat L8 & L8 T2 option. The color of the label turns brown once it has been selected. Select Done.
L8 began operating in 2012 and is continuing to collect data.
L7 began operating in 2001, but has a scan-line error that can be problematic for dates between 2005-present.
L4-5 TM, collected data from July 1982-May 2012.
Sentinel 2 A+B began operating in June 2015.
SEPAL will load a preview of your data. By default, it will show you where RGB band data is available. You can click on the RGB image at the bottom to choose from other combinations of bands or metadata.
When it is done, examine the preview to see how much data is available. For this example, coverage is good. However, in the future when you are creating your own mosaic, if there is not enough coverage of your AOI, you will need to adjust your parameters. To do so, notice the five tabs in the lower right. You can adjust the initial search parameters using the first three of these tabs (e.g. select Dat to expand the date range). The last two tabs are for Scene selection and Composite, which are more advanced filtering steps. We’ll cover those now.
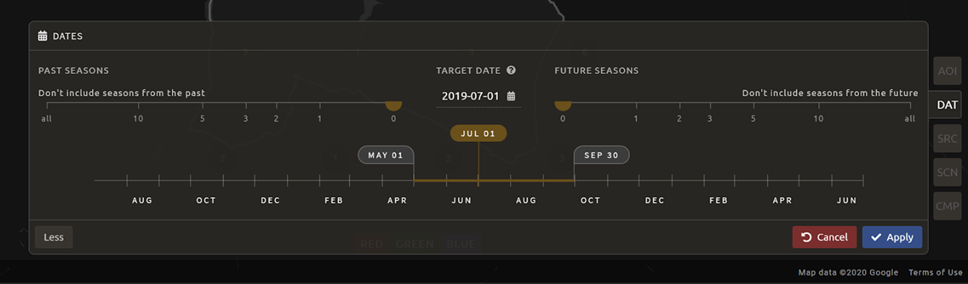
We’re now going to go through the Scene selection process. This allows you to change which specific images to include in your mosaic.
You can change the scenes that are selected using the
SCNbutton on the lower right of the screen. You can use all scenes or select which are prioritized. You can revert any changes by selectingUse All Scenesand thenApply.Change the Scenes by selecting Select scenes with Priority: Target date
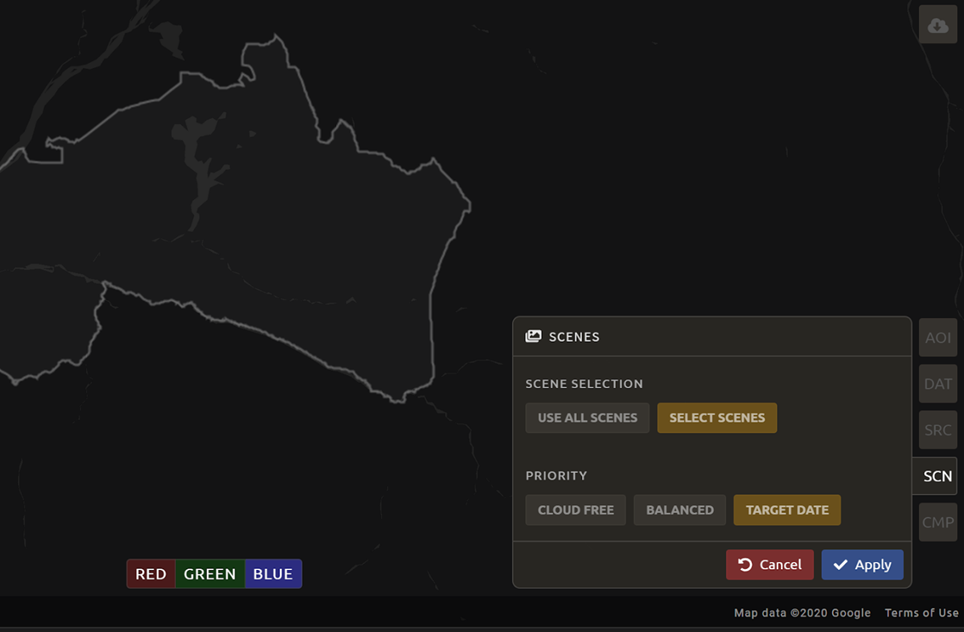
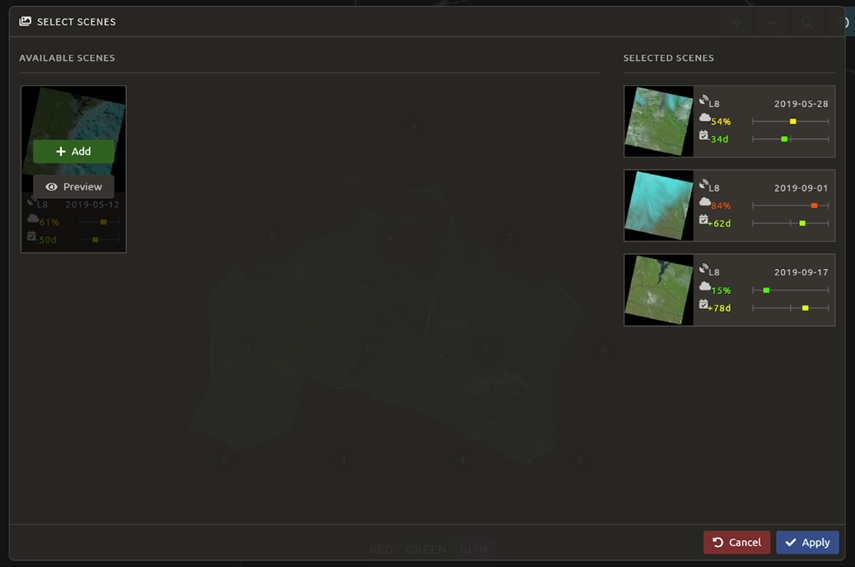
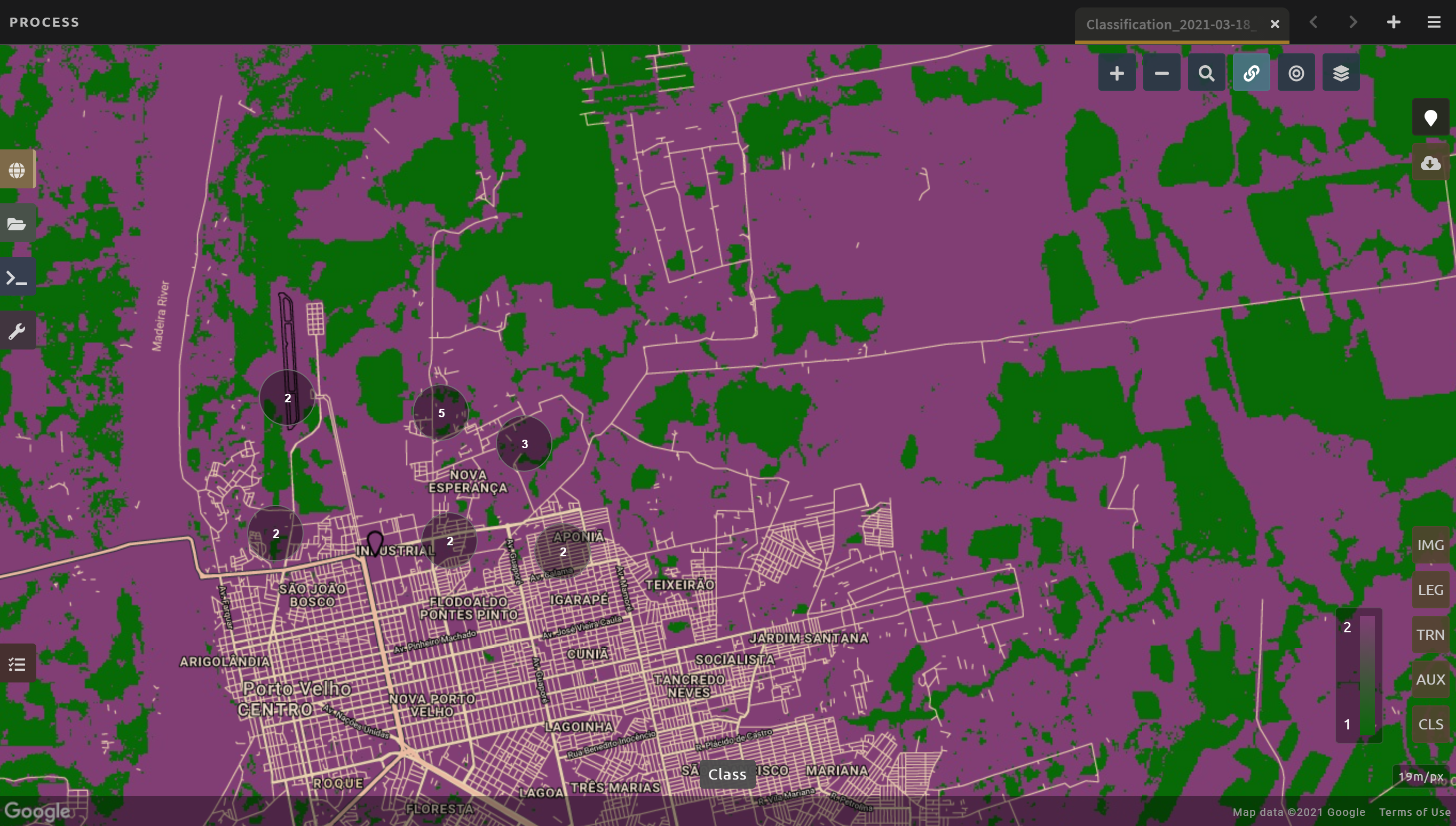
Select Apply. The result should look like the image below.
Note
Notice that the collection of circles over the Mai Ndombe study area are all populated with a zero. These represent the locations of scenes in the study area and the numbers of images per scene that are selected. The number is currently 0 because we haven’t selected the scenes yet.
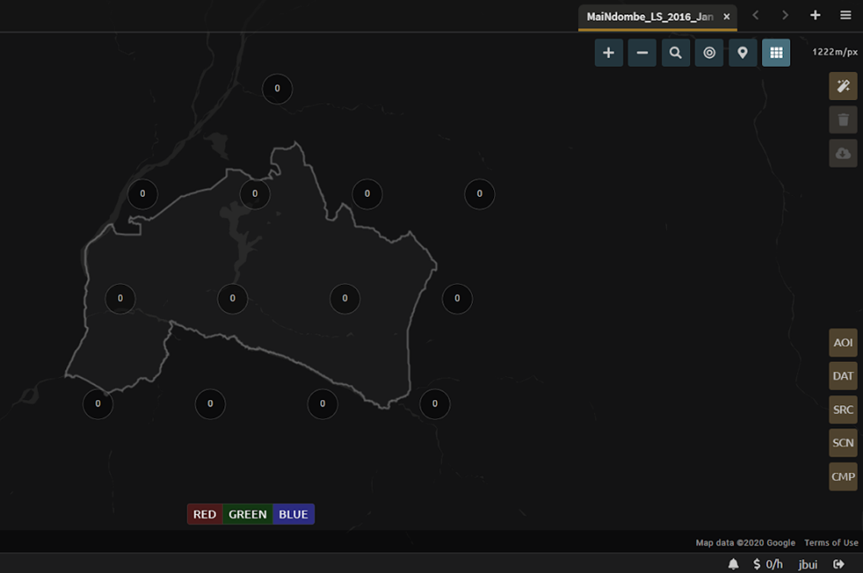
Choose the Auto-Select button to auto-select some scenes.
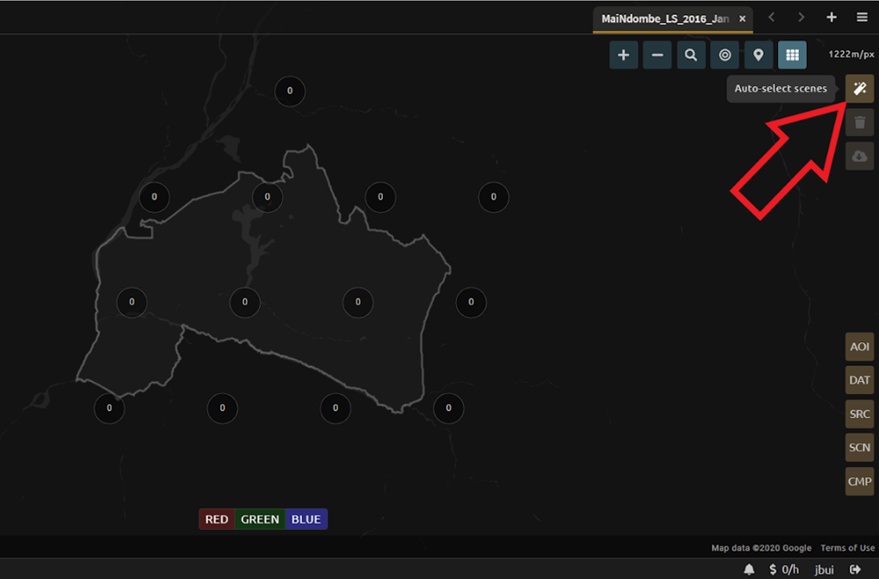
You may set a minimum and maximum number of images per scene area that will be selected. Increase the minimum to 2 and the maximum to 100. Choose Select Scenes. If there is only one scene for an area, that will be the only one selected despite the minimum.
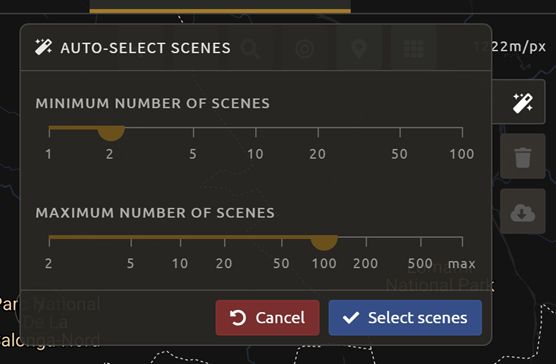
You should now see imagery with overlaying circles, indicating how many scenes are selected.
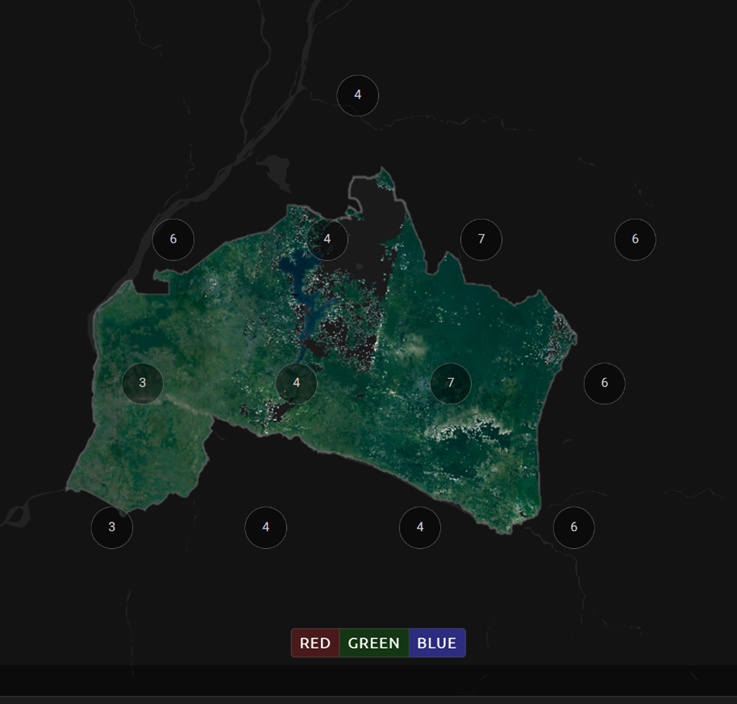
You will notice that the circles that previously displayed a O now display a variety of numbers. These numbers represent the number of Landsat images per scene that meet your specifications.
Hover over one of the circles to see the footprint (outline) of the Landsat scene that it represents. Select that circle.
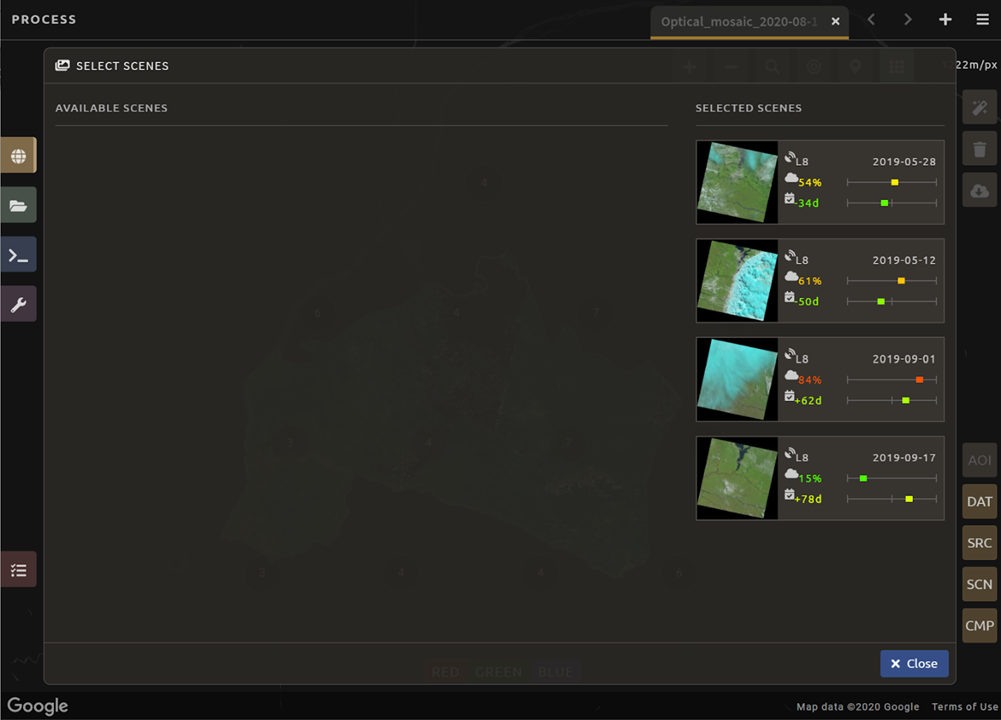
In the window that opens, you will see a list of selected scenes on the right side of the screen. These are the images that will be added to the mosaic. There are three pieces of information for each:
Satellite (e.g. L8, L7, L5 or L4)
Percent cloud cover
Number of days from the target date
To expand the Landsat image, hover over one of the images and select Preview. Click on the image to close the zoomed-in graphic and return to the list of scenes.
To remove a scene from the composite, select the Remove button when you hover over the selected scene.
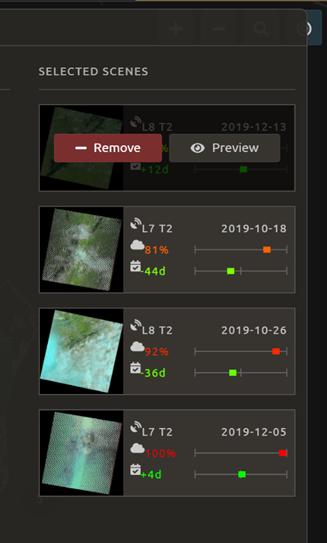
On the leftmost side, you will see Available scenes, which are images that will not be included in the mosaic, but can be added to it. If you have removed an image and would like to re-add it, or if there are additional scenes you would like to add, hover over the image and select Add.
Once you are satisfied with the selected imagery for a given area, select
Closein the lower-right corner.You can then select different scenes (represented by the circles) and evaluate the imagery for each scene.
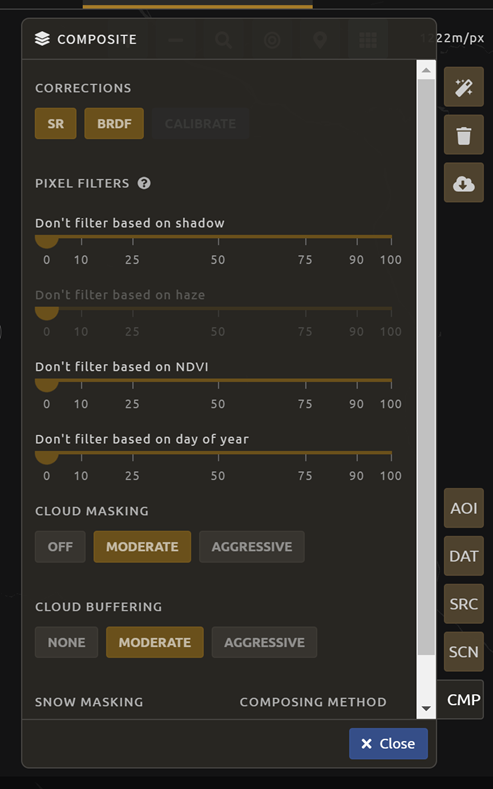
You can also change the composing method using the CMP button in the lower right.
Note
Notice that there are several additional options including shadow tolerance, haze tolerance, Normalized Difference Vegetation Index (NDVI) importance, cloud masking, and cloud buffering.
For this exercise, we will leave these at their default settings. If you make changes, select Apply after you’re done.
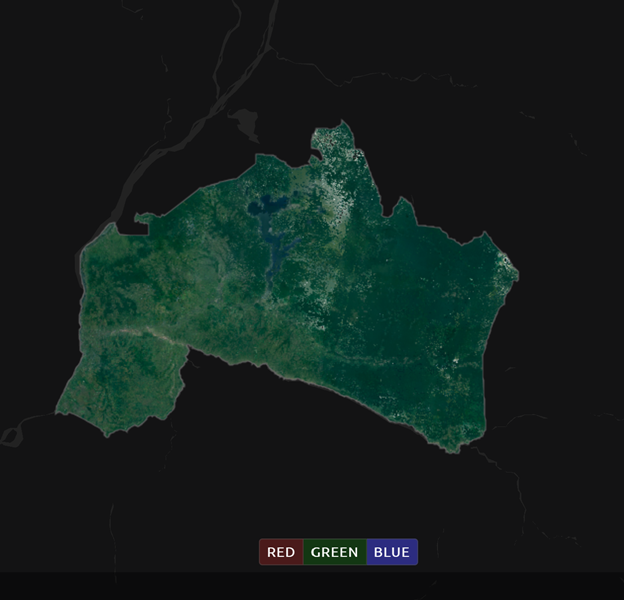
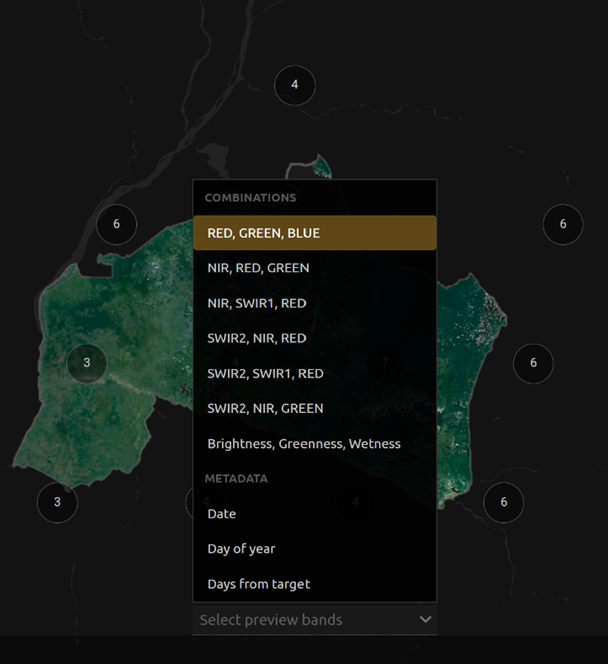
Now we’ll explore the Bands dropdown. Select Red|Green|Blue at the bottom of the page.
The dropdown menu will appear, as seen below.
Select the NIR, RED, GREEN band combination (NIR stands for near infrared). This band combination displays vegetation as red (darker reds indicate dense vegetation); bare ground and urban areas appear grey or tan; water appears black.
Once selected, the preview will automatically show what the composite will look like.
Use the scroll wheel on your mouse to zoom in on the mosaic; then, click and move to pan around the image. This will help you assess the quality of the mosaic.
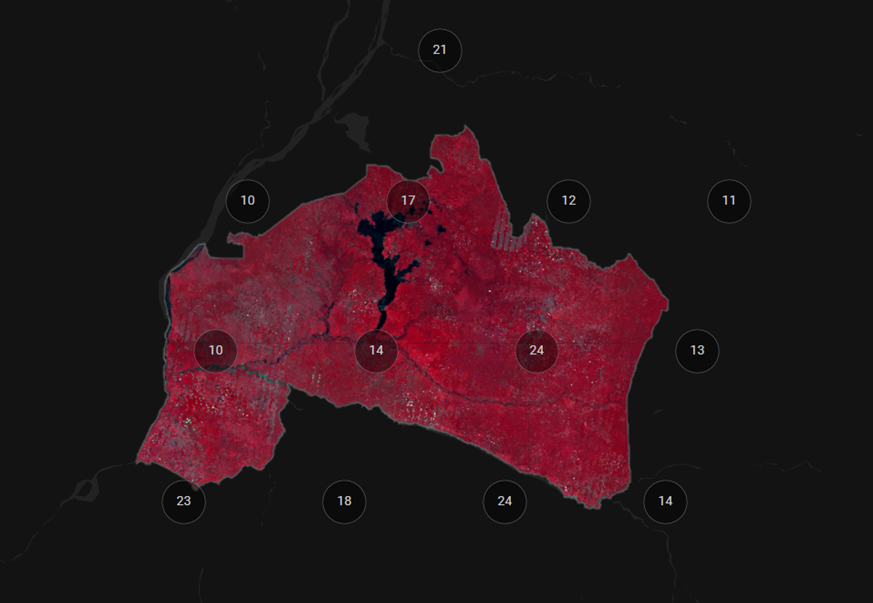
The map now shows the complete mosaic that incorporates all user-defined settings. Here is an example (yours may look different depending on which scenes you chose).
Using what you’ve learned, take some time to explore adjusting some of the input parameters and examine the influence on the output. Once you have a composite you are happy with, we will download the mosaic (instructions follow). For example, if you have too many clouds in your mosaic, then you may want to adjust some of your settings or choose a different time of year when there is a lower likelihood of cloud cover. The algorithm used to create this mosaic attempts to remove all cloud cover, but is not always successful in doing so. Portions of clouds often remain in the mosaic.
Name and save your recipe and mosaic#
Now, we will name the recipe for creating the mosaic and explore options.
Note
You will use this recipe when working with the classification or change detection tools, as well as when loading SEPAL mosaics into SEPAL’s CEO.
Tip
You can make the recipe easier to find by naming it. Select the tab in the upper right and enter a new name. For this example, use MiaNdombe_LS8_2019_Dry.
Let’s explore options for the recipe. Select the three lines in the upper-right corner:
You can Save the recipe (SEPAL will do this automatically on retrieval) so that it is available later.
You can also Duplicate the recipe. This is useful for creating two years of data, which we will do in Module 3.
Finally, you can Export the recipe. This downloads a ZIP file with a JavaScript Object Notation (JSON) of your mosaic specifications.
Select Save recipe…. This will also let you rename the mosaic, if you choose.
If you click on the three lines icon, you should see an additional option: Revert to old revision…
Choosing this option brings up a list of auto-saved versions from SEPAL. You can use this to revert changes if you make a mistake.
Tip
Now, when you open SEPAL and click the Search option, you will see a row with this name that contains the parameters you just set.
Finally, we will save the mosaic itself. This is called “retrieving” the mosaic. This step is necessary to perform analysis on the imagery.
To download this imagery mosaic to your SEPAL account, select the Retrieve button.
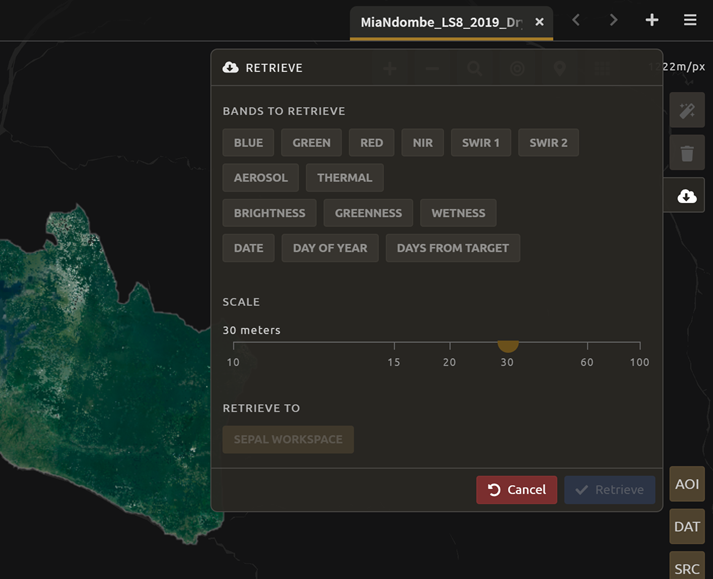
A window will appear with the following options:
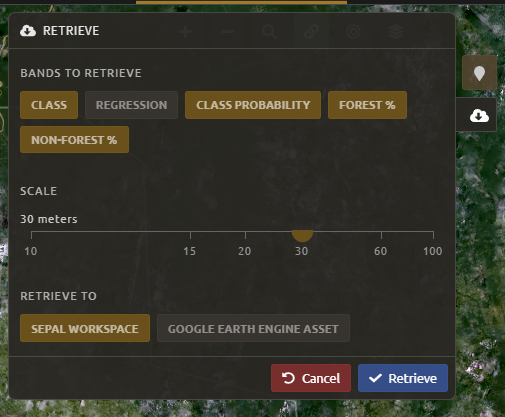
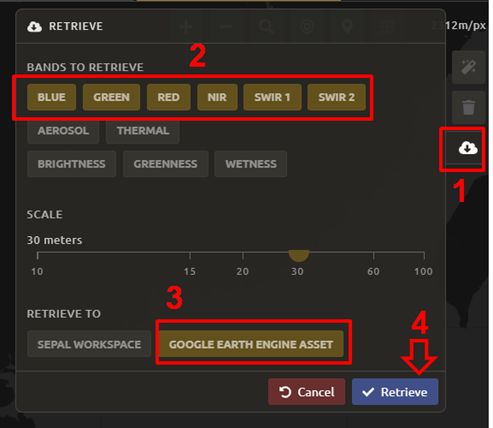
Bands to Retrieve: select the desired bands you would like to include in the download.
Select the Blue, Green, Red, NIR, SWIR 1 and SWIR 2 bands. This will show you visible and infrared data collected by Landsat.
Other bands that are available include Aerosol, Thermal, Brightness, Greenness, and Wetness (more information on these can be found at: https://landsat.gsfc.nasa.gov/landsat-data-continuity-mission).
Metadata on Date, Day of Year, and Days from Target can also be selected.
Scale: The resolution of the mosaic. Landsat data is collected at 30 metre (m) resolution, so we will leave the slider there.
Retrieve to: The SEPAL workspace is the default option. Other options may appear depending on your permissions.
When you have the desired bands selected, select Retrieve.
You will notice the Tasks icon is now spinning. If you select it, you will see that data retrieval is in process. This step will take some time.
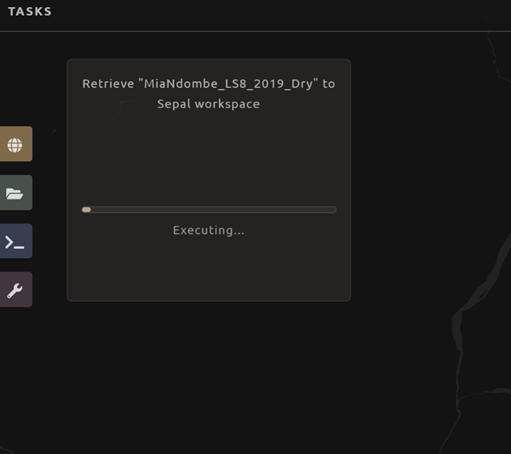
Note
This will take approximately 25 minutes to finish downloading; however, you can move on to the next exercise without waiting for the download to finish.
Image classification#
The main goal of Module 2 is to construct a single-date land cover map by classification of a Landsat composite generated from Landsat images. Image classification is frequently used to map land cover, describing what the landscape is composed of (grass, trees, water and/or an impervious surface), and to map land use, describing the organization of human systems on the landscape (farms, cities and/or wilderness).
Learning to do image classification well is extremely important and requires experience. This module was designed to help you acquire some experience. You will first consider the types of land cover classes you would like to map and the amount of variability within each class. There are both supervised (using human guidance, including training data) and unsupervised (not using human guidance) classification methods. The “random forest approach” demonstrated here uses training data and is thus a supervised classification method.
There are a number of supervised classification algorithms that can be used to assign the pixels in the image to the various map classes. One way of performing a supervised classification is to utilize a machine learning (ML) algorithm. Machine learning algorithms utilize training data combined with image values to learn how to classify pixels. Using manually collected training data, these algorithms can train a classifier, and then use the relationships identified in the training process, to classify the rest of the pixels in the map. The selection of image values (e.g. NDVI, elevation) used to train any statistical model should be thoroughly thought out and informed by your knowledge of the phenomenon of interest to classify your data (e.g. by forest, water, clouds).
In this module, we will create a land cover map using supervised classification in SEPAL. We will train a random forest machine learning algorithm to predict land cover with a user-generated reference data set. This dataset is collected either in the field or manually through examination of remotely sensed data sources, such as aerial imagery. The resulting model is then applied across the landscape. You will complete an accuracy assessment of the map output in Module 4.
Before starting your classification, you will need to create a response design with details about each of the land covers/land uses that you want to classify (Exercise 2.1); create mosaics for your area of interest (Section 2.2; we use a region of Brazil); and collect training data for the model (Exercise 2.3). Then, in Exercise 2.4, we will run the classification and examine our results.
The workflow in this module has been adapted from exercises and material developed by Dr. Pontus Olofsson, Christopher E. Holden, and Eric L. Bullock at Boston Education in Earth Observation Data Analysis (BEEODA) in the Department of Earth & Environment at Boston University. To learn more about their materials and their work, visit their GitHub site at beeoda.
At the end of this module, you will have a classified land use/land cover map.
Note
This section takes approximately four hours to complete.
Response design for classification#
Creating consistent labeling protocols is necessary for creating accurate training data and accurate sample-based estimates (see Module 4). They are especially important when more than one researcher is working on a project and for reproducible data collection. Response design helps a user assign a land cover/land use class to a spatial point. The response design is part of the metadata for the assessment and should contain the information necessary to reproduce the data collection, laying out an objective procedure that interpreters can follow and that reduces interpreter bias.
In this exercise, you will build a decision tree for your classification, as well as a significant amount of the other documentation and decision points (for more information about decision points, see Section 5.1).
Objective:
Learn how to create a classification scheme for land cover/land use classification mapping.
Specify the classification scheme#
“Classification scheme” is the name used to describe the land cover and land use classes adopted. It should cover all of the possible classes that occur in the AOI. Here, you will create a classification scheme with detailed definitions of the land cover and land use classes to share with interpreters.
Create a decision tree for your land cover or land-use classes. There may be one already in use by your department. The tree should capture the most important classifications for your study (see following example).
This example includes a hierarchical component. The green and red categories have multiple sub-categories, which might be multiple types of forest, crops or urban areas. You can also have classification schemes that are all one level with no hierarchical component.
For this exercise, we’ll use a simplified land cover and land use classification, as in this graph:
![digraph process {
lc [label="Land cover", shape=box];
f [label="Forest", shape=box, style="filled" color="darkgreen"];
nf [label="Non-forest", shape=box, style="filled", color="grey"];
lc -> f;
lc -> nf;
}](../_images/graphviz-1fb635eedd54ea4cfa901b09d422fed8789ca33e.png)
When creating your own decision tree, be sure to specify if your classification scheme was derived from a template, including the IPCC land use categories, CORINE land cover (CLC), or land cover and land use, landscape (LUCAS).
If applicable, your classification scheme should be consistent with the national land cover and land use definitions.
In cases where the classification scheme definition is different from the national definition, you will need to provide a reason.
Create a detailed definition for each land cover and land use change class included in the classification scheme. We recommend that you include measurable thresholds.
Our classification will take place in an area of the Amazon rainforest undergoing deforestation in Brazil.
We’ll define Forest as an area containing more than 70% of tree cover.
We’ll define Non-forest as areas with less than 70% of tree cover. This will capture urban areas, water and agricultural fields.
For creating your own classifications, here are some things to keep in mind:
It is important to have definitions for each of the classes. A lack of clear definitions of the land cover classes can make the quality of the resulting maps difficult to assess and challenging for others to use. The definitions you come up with now will probably be working definitions that you find you need to modify as you move through the land cover classification process.
Note
As you become more familiar with the landscape, data limitations and the ability of the land cover classification methods to discriminate some classes better than others, you will undoubtedly need to update your definitions.
As you develop your definitions, you should be relating back to your applications. Make sure that your definitions meet your project objectives. For example, if you are creating a map to be used as part of your United Nations Framework Convention on Climate Change [UNFCCC] greenhouse gas reporting documents, you will need to make sure that your definition of forest meets the needs of this application.
Note
The above land cover tree is an excerpt of text from the Methods and Guidance from the Global Forest Observations Initiative (GFOI) document that describes the IPCC Good Practice Guidance (GPG) forest definition and suggestions to consider when drafting your forest definition (2003). When creating your own decision tree, be sure to specify if your definitions follow a specific standard, such as using ISO standard Land Cover Meta-Language (LCML, ISO 19144-2) or similar.
During this online training course, you will be mapping land cover across the landscape using the Landsat composite, a moderate resolution data set. You may develop definitions based on your knowledge from the field or from investigating high-resolution imagery; however, when deriving your land cover class definitions, it’s also important to be aware of how the definitions relate to the data used to model the land cover.
Note
You will continue to explore this relationship throughout the exercise. Will the spectral signatures between your land cover categories differ? If the spectral signatures are not substantially different between classes, is there additional data you can use to differentiate these categories? If not, you might consider modifying your definitions.
For additional resources, see http://www.ipcc.ch/ipccreports/tar/wg2/index.php?idp=132
Create a mosaic for classification#
We first need an image to classify before running a classification. For best results, we will need to create an optical mosaic with good coverage of our study area. We will build upon knowledge gained in Module 1 to create an optical mosaic in SEPAL and retrieve it in GEE.
In SEPAL, you can run a classification on either a mosaic recipe or on a GEE asset. It is best practice to run a classification using an asset, rather than on the fly with a recipe. This will improve how quickly your classification will export and avoid computational limitations.
Note
Objectives:
Build on knowledge gained in Module 1.
Create a mosaic to be the basis for your classification.
Creating and exporting a mosaic for a drawn AOI#
We will create a mosaic for an area in the Amazon basin. If any of the steps for creating a mosaic are unfamiliar, please revisit Module 1.
Navigate to the Process tab, then create a new optical mosaic by selecting Optical mosaic on the Process menu.
Under Area of Interest:
Choose Draw Polygon from the dropdown list.
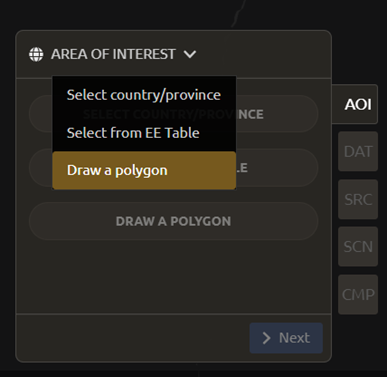
Navigate using the map to the State of Rondonia in Brazil. Draw a polygon around it or draw a polygon within the borders (note: a smaller polygon will export faster).
Now use what you have learned in Module 1 to create a mosaic with imagery from the year 2019 (the entire year of a part of the year).
Tip
Don’t forget to consider which satellites and scenes you would like to include (all or some).
Your preview should include imagery data across your entire AOI. This is important for your classification. Try also to get a cloud-free mosaic, as this makes your classification easier.
Name your mosaic for easy retrieval. Try Module2_Amazon.
When you’re satisfied with your mosaic, retrieve it to GEE. Be sure to include the red, green, blue, nir, swir1, and swir2 layers. You may choose to add other layers (e.g. greenness) as well.
Finding your GEE asset#
For future exercises, you may need to know how to find your GEE asset.
Go to https://code.earthengine.google.com and sign in.
Select the Assets tab in the leftmost column.
Under Assets, look for the name of the mosaic you just exported.
Select the mosaic name.
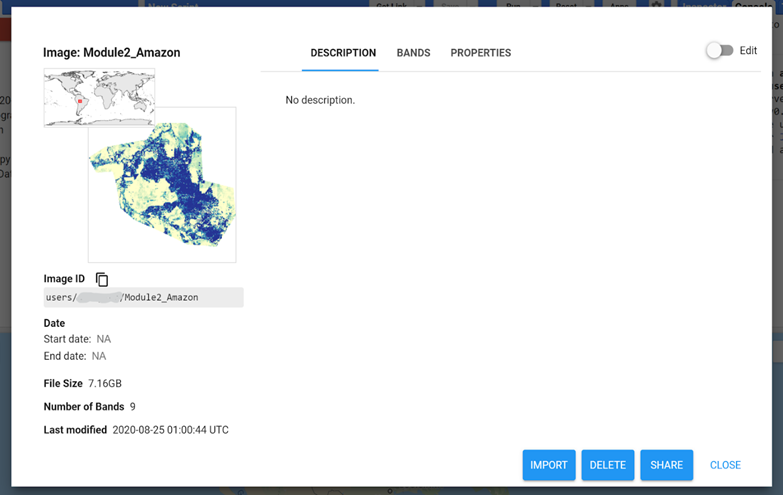
A pop-up window will appear with information about your mosaic.
Select the two overlapping boxes icon to copy your asset’s location.
Creating a classification and training data collection#
In this exercise, we will learn how to start a classification process and collect training data. These training data points will become the foundation of the classification in Section 2.4. High-quality training data is necessary to get good land cover map results. In the most ideal situation, training data is collected in the field by visiting each of the land cover types to be mapped and collecting attributes. When field collection is not an option, the second best choice is to digitize training data from high-resolution imagery, or at the very least for the imagery to be classified.
In general, there are multiple pathways for collecting training data. To create a layer of points, using desktop GIS, including QGIS and ArcGIS, is one common approach. Using GEE is another approach. You can also use CEO to create a project of random points to identify (see detailed directions in Section 4.1.2). All of these pathways will create a .csv file or a GEE table that you can import into SEPAL to use as your training data set.
However, SEPAL has a built-in reference data collection tool in the classifier. In this exercise, we will use this tool to collect training data. Even if you use a .csv file or GEE table in the future, this is a helpful feature to collect additional training data points to help refine your model.
In this assignment, you will create training data points using high-resolution imagery, including Planet NICFI data. These will be used to train the classifier in a supervised classification using SEPAL’s random forests algorithm. The goal of training the classifier is to provide examples of the variety of spectral signatures associated with each class in the map.
Objective:
Create training data for your classes that can be used to train a machine learning algorithm.
Prerequisites:
SEPAL account;
Land cover categories defined in section 2.1; and
Mosaic created in section 2.2
Set up your classification#
In the Process menu, choose the green plus symbol and select Classification.
Add the Amazon optical mosaic for classification:
Select
+ Addand choose either Saved SEPAL Recipe or Earth Engine Asset (recommended).If you choose Saved SEPAL Recipe, select your Module 2 Amazon recipe.
If you choose Earth Engine Asset, enter the Earth Engine Asset ID for the mosaic. The ID should look like “users/username/Module2_Amazon”.
Tip
Remember that you can find the link to your Earth Engine Asset ID via GEE’s Asset tab (section 2.2).
Select bands: Blue, Green, Red, NIR, SWIR1 and SWIR2. You can add other bands as well if you included them in your mosaic.
You can also include Derived bands by selecting the green button in the lower left.
Select
Apply, then selectNext.
Attention
Selecting Saved SEPAL Recipe may cause the following error at the final stage of your classification:
Google Earth Engine error: Failed to create preview
This occurs because GEE gets overloaded. If you encounter this error, please retrieve your classification as described in Section 2.2.
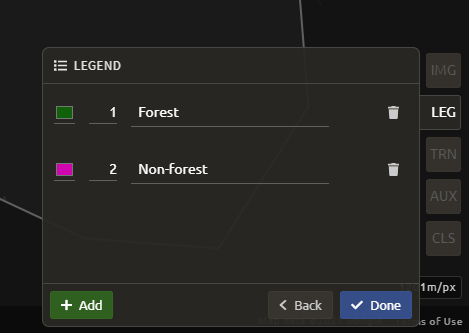
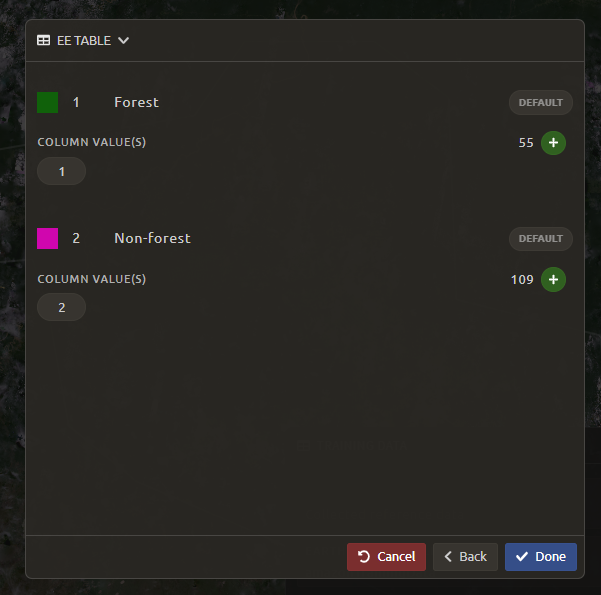
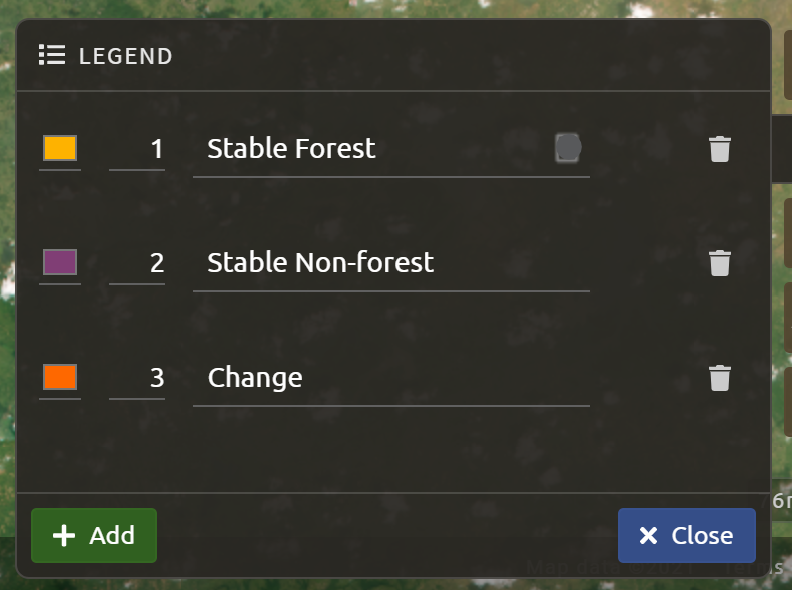
In the Legend menu, choose + Add, which creates a place for you to write your first class label.
You will need two legend entries.
The first should have the number 1 and a class label of Forest.
The second should have the number 2 and a class label of Non-forest.
Choose colors for each class as you see fit.
Select
Close.
Collect training data points#
Now that you have created your classification, you are ready to begin collecting data points for each land cover class.
In most cases, it is ideal to collect a large amount of training data points for each class that capture the variability within each class and cover the different areas of the study area. However, for this exercise, you will only collect a small number of points (approximately 25 per class). When collecting data points, make sure that your plot contains only the land cover class of interest (no plots with a mixture of your land cover categories).
Tip
To help you understand why the random forest algorithm might get some categories you are trying to map confused with others, you will use spectral signature charts in CEO-SEPAL to look at the NDVI signature of your different land cover classes. You should notice a few things when exploring the spectral signatures of your land cover classes. First, some classes are more spectrally distinct than others. For example, water is consistently dark in the NIR and MIR wavelengths, and much darker than the other classes. This means that it shouldn’t be difficult to separate water from the other land cover classes with high accuracy.
Not all pixels in the same classes have the exact same values — there is some natural variability! Capturing this variation will strongly influence the results of your classification.
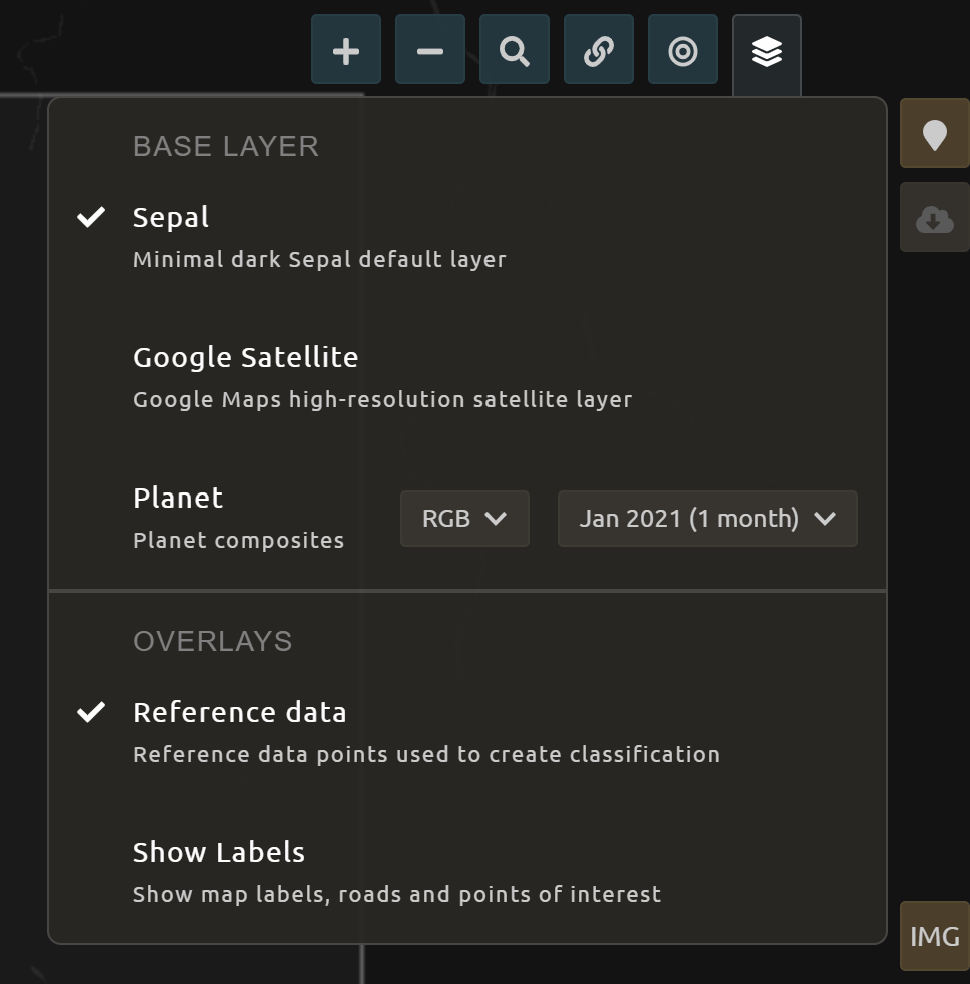
First, let’s become familiar with the SEPAL interface. In the upper-right corner of the map, there is a stack of three rectangles. If you hover over this icon, it says “Select layers to view.”
Note
Available base layers include SEPAL (minimal dark SEPAL default layer), Google Satellite, and Planet NICFI composites.
We will use the Planet NICFI composites for this example. The composites are available in either RGB or false color infrared (CIR). Composites are available monthly after September 2020 and for every 6 months prior from 2015.
Select RGB, Jun 2019 (6 months).
Tip
You can also select “Show labels” to enable labels that can help you orient yourself in the landscape.
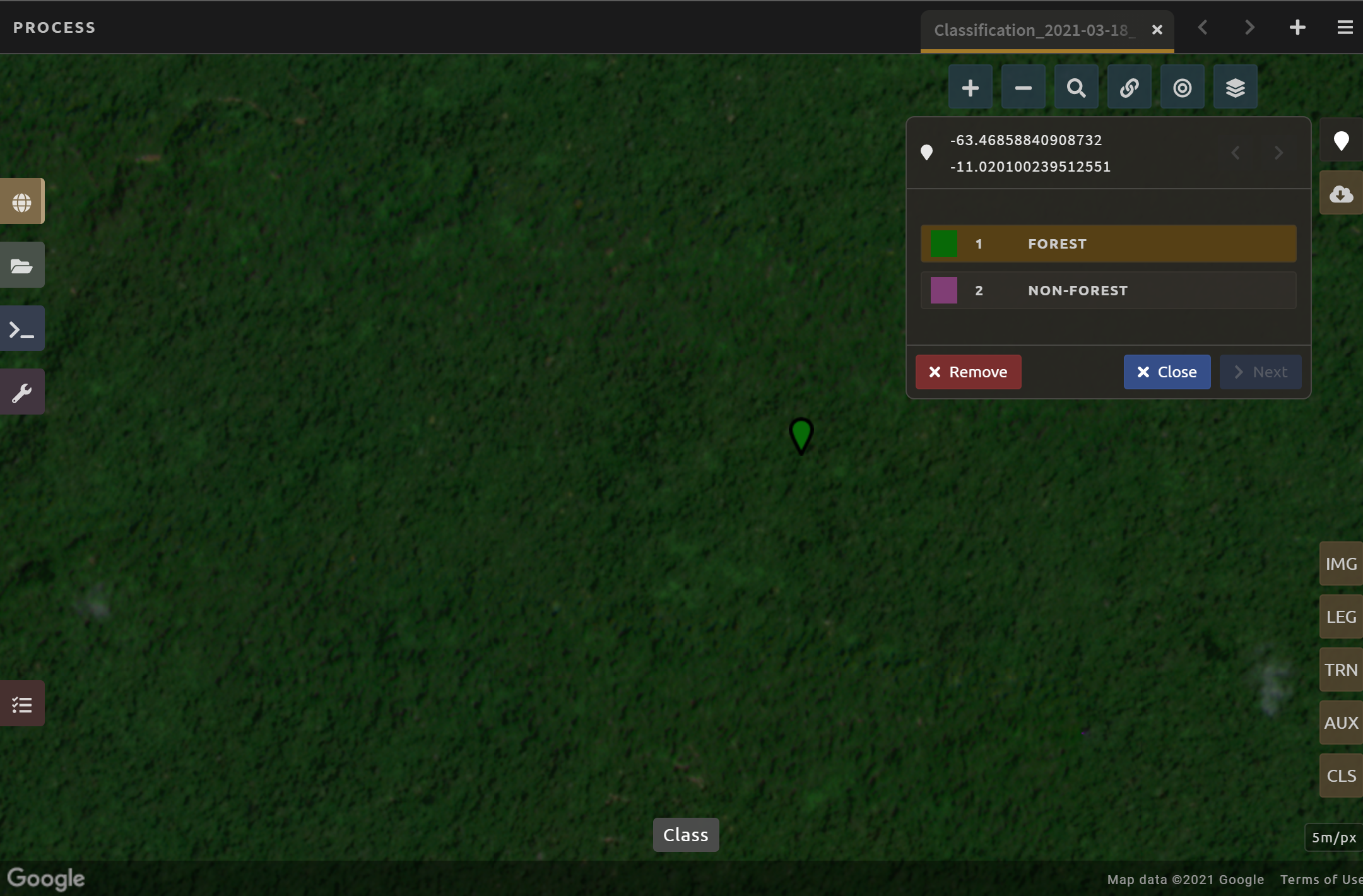
Now select the point icon. When you hover over this icon, it says “Enable reference data collection.”
With reference data collection enabled, you can start adding points to your map.
Use the scroll wheel on your mouse to zoom in on the study area. You can drag to pan around the map. Be careful though, as a single click will place a point on the map.
Tip
If you accidentally add a point, you can delete it by selecting the red Remove button.
Now we will start collecting forest training data:
Zoom into an area that is clearly forested. When you find an area that is completely forested, click it once.
You have just placed a training data point!
Select the Forest button in the training data interface to classify the point.
Tip
If you haven’t classified the point yet, you can click somewhere else on the map instead of deleting the record.
Note
Ideally you should switch back to the Landsat mosaic to make sure that this forested area is not covered with a cloud. If you mistakenly classify a cloudy pixel as Forest, then the results will be impacted negatively in the event that your Landsat mosaic does have cloud-covered areas.
However, this interface does not allow for switching between the base layer imagery and your exported mosaic. If you are using another training data collection method, keep this point in mind.
If you need to modify the classification of any of your data points, you can select the point to return to the classification (or delete) options.
Begin collecting the rest of the 25 Forest training data points throughout other parts of the study area.
The study area contains an abundance of forested land, so it should be pretty easy to identify places that can be confidently classified as forest. If you’d like, use the Charts function to ensure that there is a relatively high NDVI value for the point.
Ensure you are placing data points within the extent of the mosaic (the state of Rondonia in Brazil).
Collect about 25 points for the Forest land cover class.
Attention
When you are done, zoom out to the full extent of the area. Did you place data points somewhat equally across the full region? Are all points clustered in the same region? It’s best to make sure you have data points covering the full spatial extent of the study region; add more points in areas that are sparsely represented, if needed.
After you collect your training data for Forest, you may see the classification preview appear.
To disable the classification preview to continue to collect training data, return to the map layer selector.
Uncheck the “Classification” overlay.
Once you are satisfied with your forested training data points, move on to the Non-forest training points.
Since we are using a very basic set of land cover classes for this exercise, this should include agricultural areas, water, and buildings and roads. Therefore, it will be important that you focus on collecting a variety of points from different types of land cover throughout the study area.
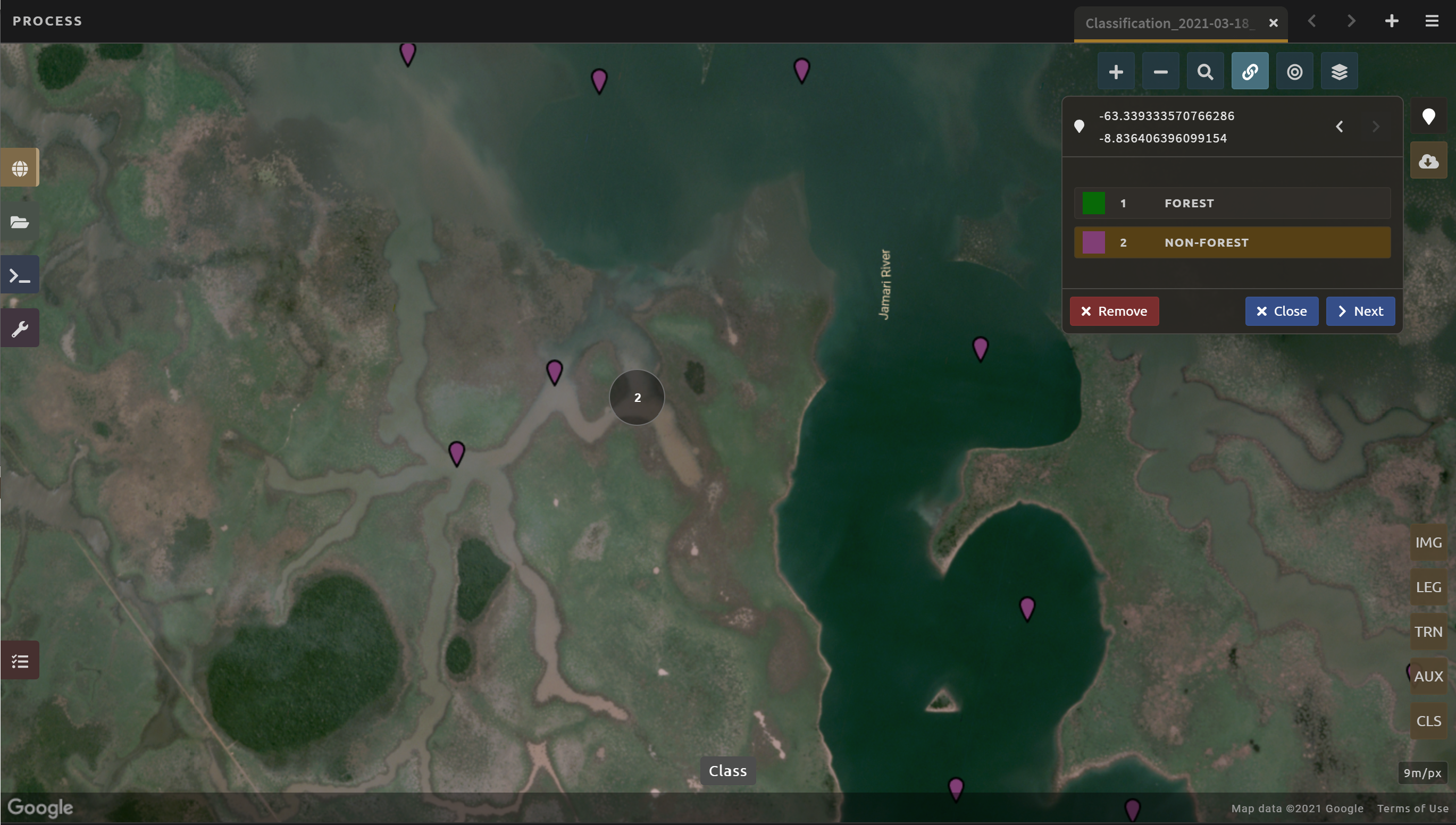
Water is one of the easiest classes to identify and the easiest to model, due to the distinct spectral signature of water.
Look for bodies of water within Rondonia.
Collect 10-15 data points for Water and be sure to spread them throughout Lake Mai Ndombe, the water sources feeding into it, and a couple of the bodies of water (including rivers) to the eastern side of the mosaic. Be sure to put 2-3 points on rivers.
Some wetland areas may have varying amounts of water throughout the year, so it is important to check both Planet NICFI maps for 2019 (Jun 2019 and Dec 2019).
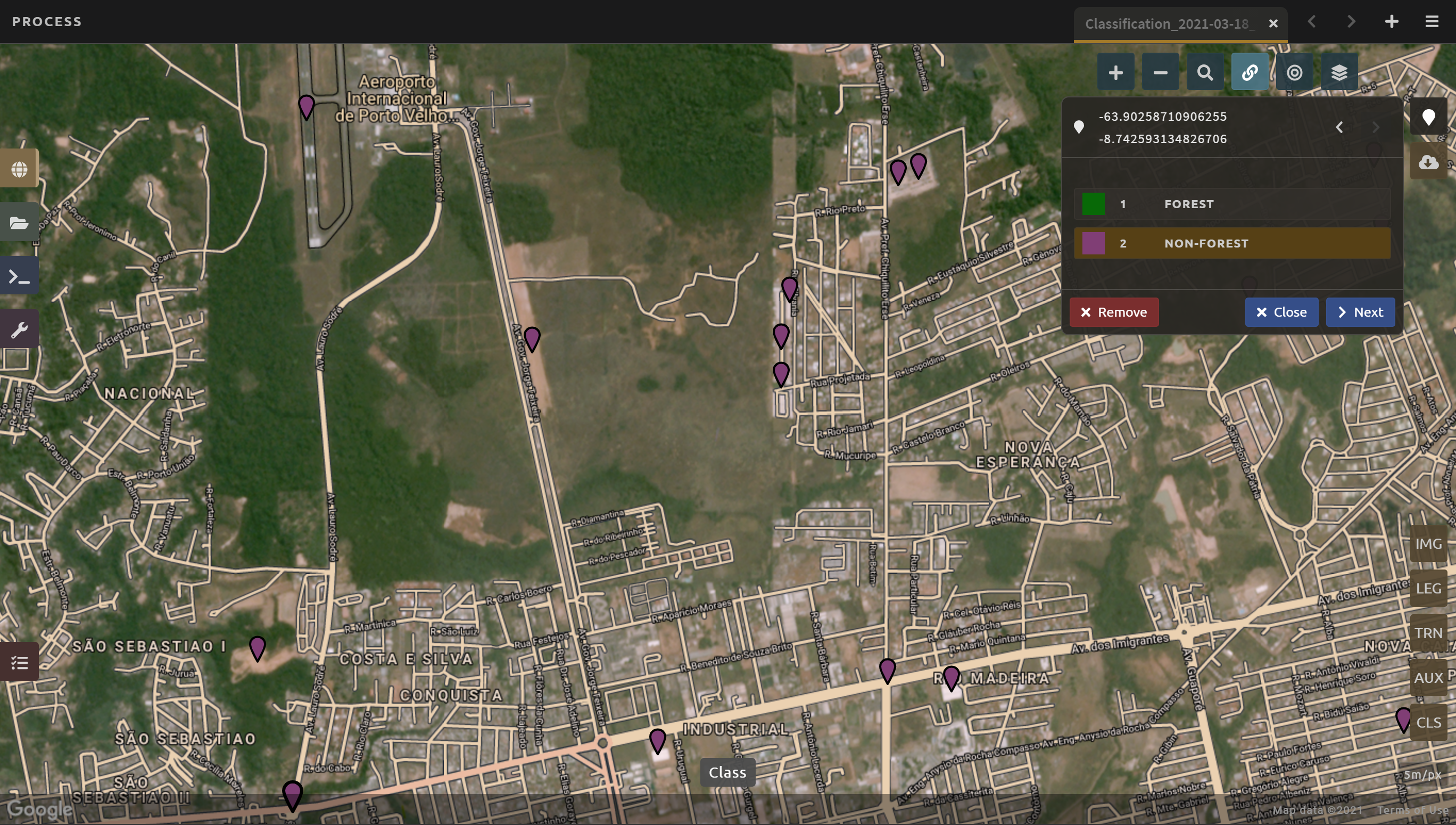
Let’s now collect some building and road non-forest training data.
There are not many residential areas in the region. However, if you look, you can find homes with dirt roads and some airports.
Place a point or points within these areas and classify them as Non-forest. Do your best to avoid placing the points over areas of the town with lots of trees.
Find some roads, and place points and classify as Non-forest. These may look like areas of bare soil. Both bare soil and roads are classified as Non-forest, so place some points on both.
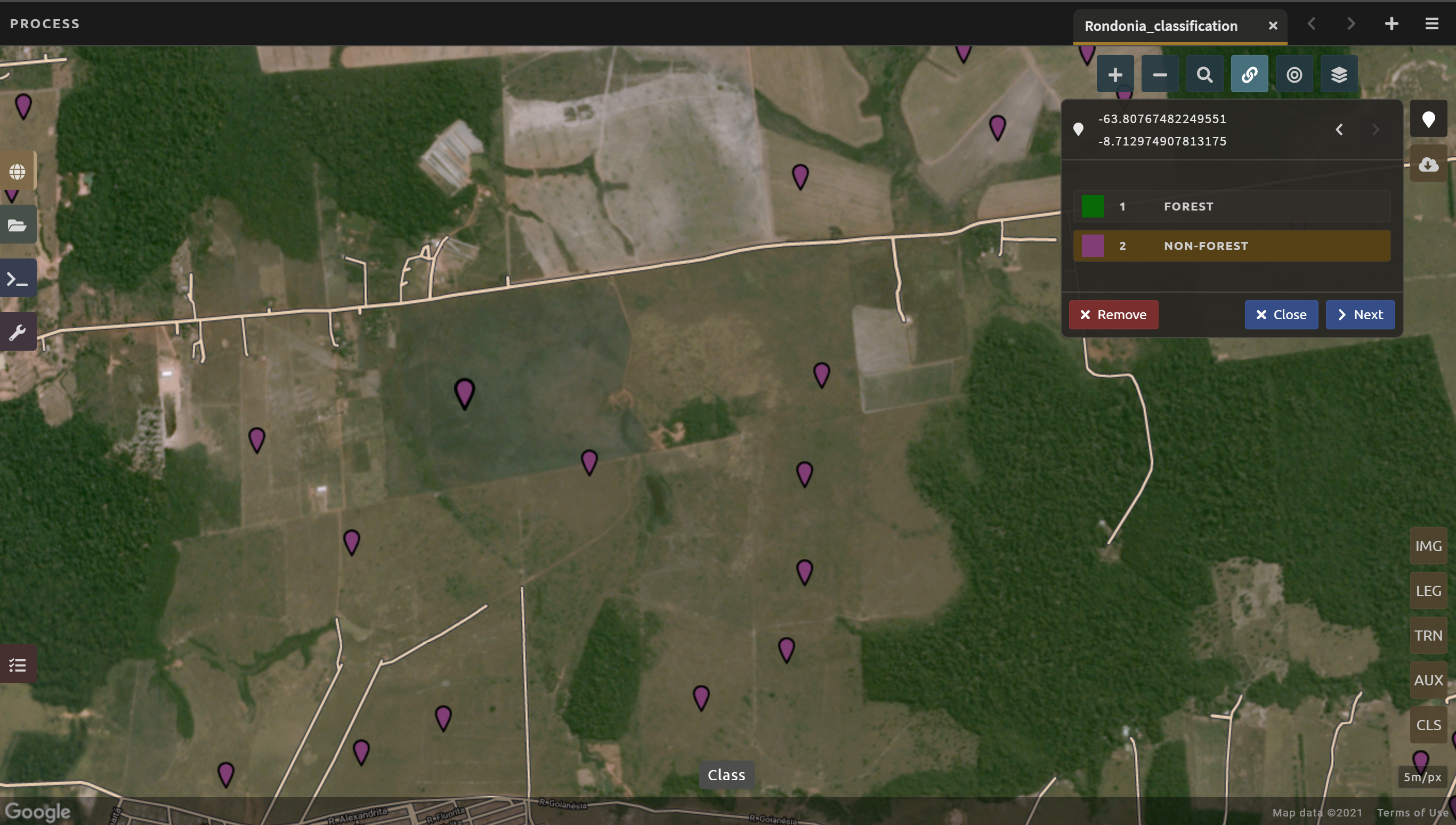
Next, place several points in grassland/pasture, shrub, and agricultural areas around the study area.
Shrubs or small, non-forest vegetation can sometimes be hard to identify, even with high-resolution imagery. Do your best to find vegetation that is clearly not forest.
The texture of the vegetation is one of the best ways to differentiate between trees and grasses/shrubs. Look at the below image and notice the clear contrast between the area where the points are placed and the other areas in the image that have rougher textures and that create shadows.
Note
If you are using QGIS (or similar) to collect training data, you should also collect Cloud training data in the Non-forest class – if your Landsat has any clouds. If there are some clouds that were not removed during the Landsat mosaic creation process you will need to create training data for the clouds that remain so that the classifier knows what those pixels represent. Sometimes clouds were detected during the mosaic process and were mostly removed. However, you can see that some of the edges of those clouds remain.
Note that you may not have any clouds in your Landsat imagery.
Continue collecting Non-forest points. Again, be sure to spread the points out across the study area.
When you are done collecting data for these categories, zoom out to the full extent of the study region.
Did you place data points somewhat equally across the full region?
Are all points clustered in the same area?
It’s best to make sure you have data points covering the full spatial extent of the study region; add more points in areas that are sparsely represented, if needed.
Classification using machine learning algorithms (Random Forests)#
As mentioned in the module introduction, the classification algorithm you will be using today is called Random forest, which creates numerous decision trees for each pixel. Each of these decision trees votes on what the pixel should be classified as. The land cover class that receives the most votes is then assigned as the map class for that pixel. Random forests are efficient on large data and accurate when compared to other classification algorithms.
To complete the classification of our mosaicked image, you are going to use a random forests classifier contained within the easy-to-use Classification tool in SEPAL. The image values used to train the model include the Landsat mosaic values and some derivatives, if selected (such as NDVI). There are likely additional datasets that can be used to help differentiate land cover classes such as elevation data.
After we create the map, you might find that there are some areas that are not classifying well. The classification process is iterative, and there are ways you can modify the process to get better results. One way is to collect more or better reference data to train the model. You can test different classification algorithms, or explore object-based approaches, opposed to pixel-based approaches. The possibilities are many and should relate back to the nature of the classes you hope to map. Last, but certainly not least, is to improve the quality of your training data. Be sure to log all of these decision points in order to recreate your analysis in the future.
Objective:
Run SEPAL’s classification tool.
Prerequisites:
land cover categories defined in Section 2.1;
mosaic created in Section 2.2; and
training data created in Section 2.3.
Add training data collected outside of SEPAL#
Note
This section is optional.
If you collected training data using QGIS, CEO, or another pathway, you will need to add the Training Data we collected in Section 2.3 in the TRN tab.
Select the green Add button.
Import your training data - Upload a .csv file. - Select Earth Engine Table and enter the path to your Earth Engine asset in the EE Table ID field.
Select
Next.For Location Type, select X/Y” coordinate columns or GEOJSON Column, depending on your data source. GEE assets will need the GEOJSON column option.
Select
Next.Leave the Row filter expression blank. For Class format, select Single Column or Column per class, as your data dictates.
In the Class Column field, select the column name that is associated with the class.
Select
Next.
Now you will be asked to confirm the link between the legend you entered previously and your classification. You should see a screen as follows. If you need to change anything, select the green plus buttons. Otherwise, select Done, then select Close.
Review additional classification options#
Select AUX to examine the auxiliary data sources available for the classification.
Auxiliary inputs are optional layers which can be added to help aid the classification. There are three additional sources available:
Latitude: includes the latitude of each pixel;
Terrain: includes elevation of each pixel from SRTM data; and
Water: includes information from the JRC Global Surface Water Mapping layers
Select Water and Terrain and then Apply.
Select CLS to examine the classifier being used.
The default is a Random forest with 25 trees.
Other options include classification and regression trees (CART), Naive Bayes, support vector machine (SVM), minimum distance, and decision trees (requires a .csv file).
Additional parameters for each of these can be specified by selecting the More button in the lower left.
For this example, we will use the default, Random forest with 25 trees.
If you turned off your classification preview previously to collect training data, now is the time to turn it back on.
Select the Select layers to show icon.
Select Classification.
Make sure Classification now has a check mark next to it, indicating that the layer is now turned on.
Now we’ll save our classification output.
First, rename your classification by entering a new name in the tab.
Select
Retrieve classificationin the upper-right hand corner (cloud icon).Choose 30 m resolution.
Select the Class, Class probability, Forest % and Non-forest % bands.
Retrieve to your SEPAL workspace.
Note
You can also choose Google Earth Engine Asset if you would like to be able to share your results or perform additional analysis in GEE; however, with this option, you will need to download your map from GEE using the export function.
Once the download begins, you will see the spinning wheel in the lower-left of the webpage in Tasks. Select the spinning wheel to observe the progress of your export.
When complete, if you chose SEPAL workspace, the file will be in your SEPAL downloads folder. (Browse > downloads > classification name folder). If you chose GEE Asset, the file will be in your GEE Assets.
QA/QC considerations and methods#
Quality assurance and quality control, commonly referred to as QA/QC, is a critical part of any analysis. There are two approaches to QA/QC: formal and informal. Formal QA/QC, specifically sample-based estimates of error and area, are described in Module 4. Informal QA/QC involves qualitative approaches to identifying problems with your analysis and classifications to iterate and create improved classifications.
Here we’ll discuss one approach to informal QA/QC.
Following analysis, you should spend some time looking at your change detection in order to understand if the results make sense. We’ll do this in the classification window. This allows us to visualize the data and collect additional training points if we find areas of poor classification. Other approaches not covered here include visualizing the data in GEE or another program, such as QGIS or ArcMAP.
With SEPAL, you can examine your classification and collect additional training data to improve the classification.
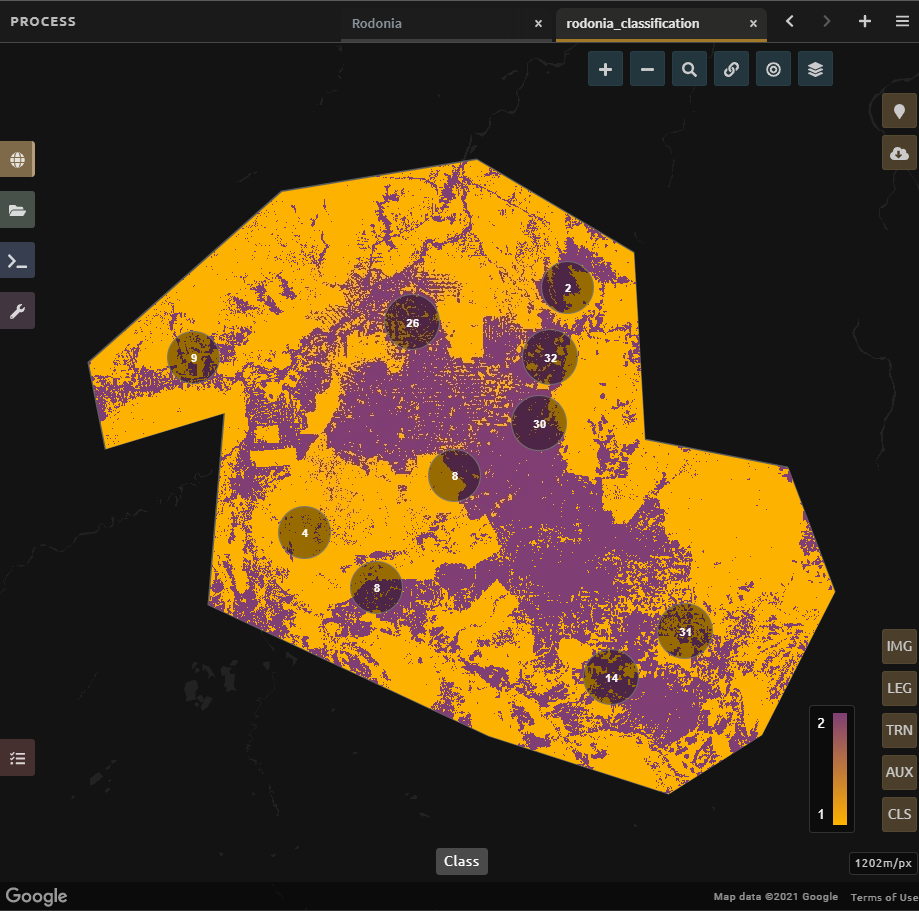
Turn on the imagery for your classification; pan and zoom around the map. Compare your classification map to the 2015 and 2020 imagery. Where do you see areas that are correct? Where do you see areas that are incorrect? If your results make sense, and you are happy with them, continue to formal QA/QC in Module 4.
Note
If you are not satisfied, collect additional points of training data where you see inaccuracies. Then, re-export the classification following the steps in Section 2.3.
Image change detection#
Image change detection allows us to understand differences in the landscape as they appear in satellite images over time. There are many questions that change detection methods can help answer, including: “When did deforestation take place?” and “How much forest area has been converted to agriculture in the past five years?”
Most methods for change detection use algorithms supported by statistical methods to extract and compare information in the satellite images. To conduct change detection, we need multiple mosaics or images, each one representing a point in time.
In this section of SEPAL documentation, we will describe how to detect change between two dates using a simple model (note: this theory can be expanded to include more dates as well). In addition, we’ll describe time series analysis, which generally looks at longer periods of time.
The objective of this module is to become associated with methods of detecting change for an AOI using the SEPAL platform. We will build upon and incorporate what we have covered in the previous modules, including: creating mosaics, creating training samples, and classifying imagery.
This module is split into two exercises: the first addresses change detection using two dates; the second demonstrates more advanced methods using time series analysis with the BFAST algorithm and LandTrendr.
At the end of this module, you will know how to conduct a two-date change detection in SEPAL, have a basic understanding of the BFAST tool in SEPAL, and be familiar with TimeSync and LandTrendr.
This module should take you approximately three hours to complete.
Two-date change detection#
In this exercise, you will learn how to conduct a two-date change detection in SEPAL with the same classification algorithm used in Module 2.
This approach can be used with more than two dates in the future, if needed.
In this example, you will create optical mosaics and classify them, building on skills learned in Module 1 and Module 2.
You may use two classifications from your own research area, if you prefer.
Note
Prerequisites:
Create mosaics for change detection#
Before we can identify change, we first need to have images to compare.
In this section, we will create two mosaics of Sri Lanka, generate training data, and then classify the mosaics. This is discussed in detail in Module 1 and Module 2.
Open the Process menu and select Optical mosaic. Alternatively, select the green plus symbol to open the Create recipe menu; then, select Optical mosaic.
Use the following data:
Choose Sri Lanka for the AOI.
Select 2015 for the date (DAT).
Select Landsat 8 (L8) as the source (SRC).
In the Composite (CMP) menu, ensure that surface reflectance ((SR) correction) is selected, as well as Median as the compositing method.
Select Retrieve mosaic; then select Blue, Green, Red, NIR, SWIR1, SWIR2. Lastly, select Google Earth Engine Asset and Retrieve.
Note
If you don’t see the Google Earth Engine Asset option, you need to connect your Google account to SEPAL by selecting your username in the lower right.
Repeat previous steps, but change the Date parameter to 2020.
Note
It may take a significant amount of time before your mosaics finish exporting.
Start the classification#
Now we will begin the classification, as we did in Module 2. There are multiple pathways for collecting training data. To create a layer of points, using desktop GIS, including QGIS and ArcGIS, is one common approach. Using GEE is another approach. You can also use CEO to create a project of random points to identify (see detailed directions in Section 4.1.2). All of these pathways will create a .csv file or a GEE table that you can import into SEPAL to use as your training data set.
SEPAL has a built-in reference data collection tool in the classifier. This is the tool you used in Module 2, and we will again use this tool to collect training data. Even if you use a .csv file or GEE table in the future, this is a helpful feature to collect additional training data points to help refine your model.
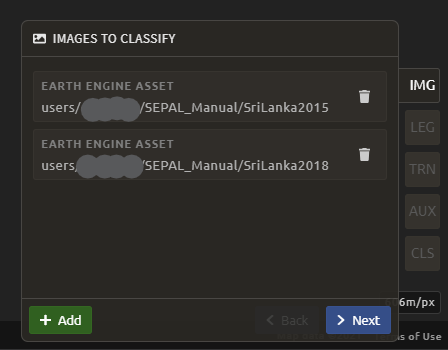
In the Process menu, select the green plus symbol and select Classification.
Add the two Sri Lanka optical mosaics for classification by selecting + Add and choose either Saved SEPAL Recipe or Earth Engine Asset (recommended).
If you choose Saved SEPAL Recipe, simply select your Module 2 Amazon recipe.
If you choose Earth Engine Asset, enter the Earth Engine Asset ID for the mosaic. The ID should look like “users/username/SriLanka2015”.
Tip
Remember that you can find the link to your Earth Engine Asset ID via GEE’s Asset tab (see Exercise 2.2 Part 2).
Select bands: Blue, Green, Red, NIR, SWIR1, and SWIR2. You can add other bands as well, if you included them in your mosaic. You can also include Derived bands by selecting the green button in the lower left and selecting Apply.
Repeat the previous steps for your 2020 optical mosaic.
Attention
Selecting Saved SEPAL recipe may cause the following error at the final stage of your classification:
Google Earth Engine error: Failed to create preview.
This occurs because GEE gets overloaded. If you encounter this error, please retrieve your classification as described in section 2.2.
Collect change classification training data#
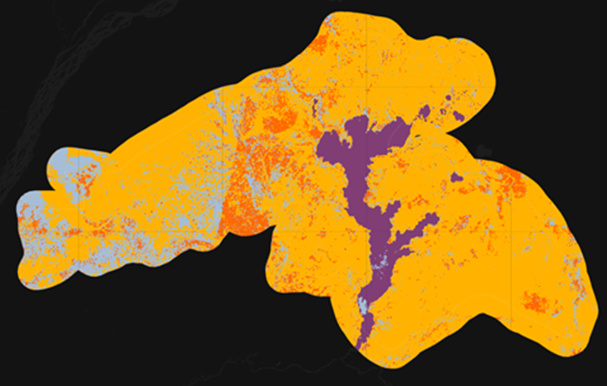
Now that we have the mosaics created, we will collect change training data. While more complex systems can be used, we will consider two land cover classes that each pixel can be in 2015 or 2020: forest and non-forest. Thinking about change detection, we will use three options: stable forest, stable non-forest, and change. That is, between 2015 and 2020, there are four pathways: a pixel can be forest in 2015 and in 2020 (stable forest); a pixel can be non-forest in 2015 and in 2020 (stable non-forest); or it can change from forest to non-forest or from non-forest to forest. If you use this manual to guide your own change classification, remember to log your decisions including how you are thinking about change detection (what classes can change and how), and the imagery and other settings used for your classification.
![digraph G {
rankdir=LR;
subgraph cluster0 {
node [style=filled, shape=box];
a0 [label="Non-forest", color=lightgrey];
a1 [label="Forest", color=darkgreen];
label = "2015";
}
subgraph cluster1 {
node [style=filled, shape=box];
b0 [label="Non-forest", color=lightgrey];
b1 [label="Forest", color=darkgreen];
label = "2018";
}
a0 -> b0 [color=grey];
a1 -> b1 [color=darkgreen];
a1 -> b0 [color=orange];
a0 -> b1 [color=orange];
}](../_images/graphviz-6cfd6921b4e1bc1e1af4c96888889efdf86827dc.png)
In the Legend menu, select + Add. This will add a place for you to write your first class label. You will need three legend entries:
The first should have the number 1 and a class label of Forest.
The second should have the number 2 and a class label of Non-forest.
The third should have the number 3 and a class label of Change.
Choose colors for each class as you see fit and select Close.
Now, we’ll create training data. First, let’s pull up the correct imagery. Choose Select layers to view. As a reminder, available base layers include: - SEPAL (Minimal dark SEPAL default layer) - Google Satellite - Planet NICFI composites
We will use the Planet NICFI composites for this example. The composites are available in either RGB or false color infrared (CIR). Composites are available monthly after September 2020 and for every six months prior through 2015. Select Dec 2015 (six months). Both RGB and CIR will be useful, so choose whichever you prefer. You can also select Show labels to enable labels that can help you orient yourself in the landscape. You will need to switch between this Dec 2015 data and the Dec 2020 data to find stable areas and changed areas.
Note
If you have collected data in QGIS, CEO or another program, you can skip the following steps. Simply select TRN in the lower right. Select + Add, then upload your data to SEPAL. Finally, select the CLS button in the lower right and you can skip to Section 3.1.4
Now select the point icon. When you hover over this icon, it says Enable reference data collection.
With reference data collection enabled, you can start adding points to your map.
Use the scroll wheel on your mouse to zoom in on the study area. You can drag to pan around the map. Be careful though, as a single click will place a point on the map.
Tip
If you accidentally add a point, you can delete it by selecting the red Remove button.
Collect training data for the Stable forest class. Place points where there is forest in both 2015 and 2020 imagery. Then collect training data for the Stable Non-forest class. Place points where there is not forest in either 2015 or 2020. You should include water, built-up areas, bare dirt, and agricultural areas in your points. Finally collect training data for the Change class.
Tip
If you are having a hard time finding areas of change, several tools can help you:
You can use Google satellite imagery to help. Areas of forest loss often appear as black or dark purple patches on the landscape. Be sure to always check the 2015 and 2020 Planet imagery to verify Change.
The CIR (false color infrared) imagery from Planet can also be helpful in identifying areas of change.
- You can also use SEPAL’s on-the-fly classification to help after collecting a few Change points.
If the classification does not appear after collecting the Stable forest and Stable non-forest classes, select the “Select layers to view” icon.
Toggle the Classification option off, and then on again.
You may need to select CLS on the lower right of the screen, then select Close to get the classification map to appear.
With the classification map created, you can find change pixels and confirm whether they are change or not by comparing 2015 and 2020 imagery.
One trick for determining change is to place a Change point in an area of suspected change. Then you can compare 2015 and 2020 imagery without losing the place you were looking at. If it is not change, you can switch which classification you have identified the point as.
Continue collecting points until you have approximately 25 points for Forest and Non-forest classes and about 5 points for the Change class. More is better. Try to have your points spread out across Sri Lanka.
If you need to modify the classification of any of your data points, you can select the point to return to the classification options. You can also remove the point in this way.
When you are happy with your data points, select the AUX button in the lower right. Select Terrain and Water. This will add auxiliary data to the classification.
Finally select the CLS button in the lower right. You can change your classification type to see how the output changes. If it has not already, SEPAL will now load a preview of your classification.
Two-date classification retrieval#
Now that the hard work of setting up the mosaics and creating and adding the training data is complete, all that is left to do is retrieve the classification.
To retrieve your classification, select the cloud icon in the upper right to open the Retrieve pane.
Select Google Earth Engine Asset if you would like to share your map or if you would like to use it for further analysis.
Select SEPAL workspace if you would like to use the map internally only.
Then, use the following parameters:
Resolution: 30 m resolution
Selected bands: the Class, Class probability, Forest % and Non-forest % bands.
Finally, select Retrieve.
Quality assurance and quality control#
Quality assurance and quality control (QA/QC) is a critical part of any analysis. There are two approaches to QA/QC: formal and informal. Formal QA/QC, specifically sample-based estimates of error and area are described in Module 4. Informal QA/QC involves qualitative approaches to identifying problems with your analysis and classifications to iterate and create improved classifications. Here we’ll discuss one approach to informal QA/QC.
Following analysis, you should spend some time looking at your change detection in order to understand if the results make sense. This allows us to visualize the data and collect additional training points if we find areas of poor classification. Other approaches not covered here include visualizing the data in GEE or in another program, such as QGIS or ArcMAP.
With SEPAL, you can examine your classification and collect additional training data to improve the classification.

Turn on the imagery for your classification; pan and zoom around the map.
Compare your classification map to the 2015 and 2020 imagery. Where do you see areas that are correct? Where do you see areas that are incorrect?
If your results make sense and you are happy with them, continue to formal QA/QC in Module 4.
Note
If you are not satisfied, collect additional points of training data where you see inaccuracies. Then re-export the classification following the steps in Section 3.1.3.
Deforest tool#
The DEnse FOREst Time Series (deforest) tool is a method for detecting changes in forest cover in a time series of Earth observation data. As input, it takes a time series of forest probability measurements, producing a map of deforestation and an “early warning” map of unconfirmed changes. The method is based on the “Baysian time series” approach of Reiche et al. (2018).
The tool was designed as part of the Satellite Monitoring for Forest Management (SMFM) project, which aimed to address global challenges relating to the monitoring of tropical dry forest ecosystems. It was conducted in partnership with teams in Mozambique, Namibia and Zambia (for more information, see https://www.smfm-project.com).
Full documentation is hosted at http://deforest.rtfd.io
This module should take you approximately one to two hours to complete.
Data preparation#
For this exercise, we will be using the sample data that is included with the tool. Additionally, instructions are given on how to create a time series of forest probability using tools with the SEPAL platform.
Objectives |
Prerequisites |
|---|---|
Learn how to use the SMFM Deforest tool |
SEPAL account |
Completed SEPAL modules on mosaics, classification and time series |
Jupyter notebook basics (optional)#
If you are unfamiliar with Jupyter notebooks, this section is meant to get you acquainted enough with the system to successfully run the SMFM Deforest tool. A notebook is significantly different than most SEPAL applications, but they are a powerful tool used in data science and other disciplines.
Cells
Every notebook is broken into cells. Cells can come in a few formats, but typically they will be either markdown or code. Markdown cells are the descriptive text and images that accompany the code to help a user understand the context and what the code is doing. Conversely, code cells run code or a system operation. There are many different languages which can be used in a Jupyter notebook. For this tool, we will be using Python.
Running cells
To run a cell, select the cell, then locate and select the Run button in the upper menu. You can run a cell more quickly using the keyboard shortcut shift-enter.
Kernel
The kernel is the computation engine that executes the code in the Jupyter notebook. In this case, it is a Python 3 kernel. For this tutorial, you do not need to know much about this, but if the notebook freezes or you need to reset it for any reason, you can find kernel operations in the toolbar menu.
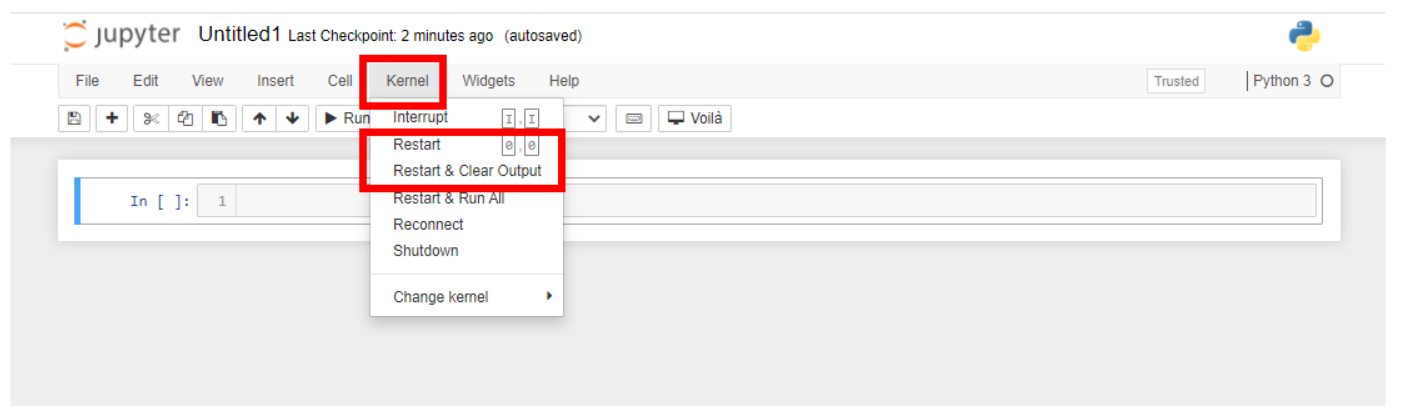
Restarting the kernel:
Go to the toolbar at the top of the notebook and select Kernel.
From the dropdown menu, select Restart Kernel and clear outputs.
Preparing your data#
For this exercise, we will be using the sample data that is included with the tool. Additionally, instructions are given on how to create a time series of forest probability using tools with the SEPAL platform.
Attention
SMFM Deforest is still in the process of being adapted for use on SEPAL. The forest probability time series will be derived from existing methods to produce a satellite time series implemented on SEPAL.
This tutorial will use the demo data that is packaged with the SMFM Deforest tool, but steps are presented on how to use the current SEPAL implementation with the tool. Note that the data preparation steps in SEPAL can take many hours to complete. If you are unfamiliar with any of the preparations steps, please consult the relevant modules.
If you already have a time series of percent forest coverage, feel free to use that.
Download demo data.
Go to the SEPAL Terminal.
Start a new instance or join your current instance.
Clone the deforest GitHub repository to your SEPAL account using the following command.
` git clone https://github.com/smfm-project/deforest `Use the SEPAL workflow to generate time series of forest probability images.
Create an optical mosaic for your AOI using the Process tab and selecting Optical mosaic. If this is unfamiliar to you, please see the tutorials on OpenMRV under the process, “Mosaic generation with SEPAL”.
Save the mosaic as a recipe.
Open a new classification and point to the Optical mosaic recipe as the image to classify. Use the Process tab and select the Classification process. If this is unfamiliar to you, please see the tutorials on OpenMRV under the process, “Classification”.
Select the bands you want to include in the classification.
Add forest/non-forest training data.
Sample points directly in SEPAL.
Optionally, use Earth Engine asset.
Apply the classifier.
Select the %forest output.
Save the classification as a recipe.
Open a new time series.
Select the same AOI as your mosaic.
Choose a date range for the time series.
In the ‘SRC’ box, select satellites you used in the previous steps and the classification to apply.
Download the time series to your SEPAL workspace.
Note
It will take many hours to download the classified time series to your account, depending on how large your AOI is.
Setup#
Go to the Apps menu by selecting the wrench icon and typing “SMFM” into the search field. Select “SMFM Deforest”.
Note
Sometimes the tool takes a few minutes to load. Wait until you see the tool’s interface. In case the tool fails to load properly, close the tab and repeat the steps above. If this does not work, reload SEPAL.
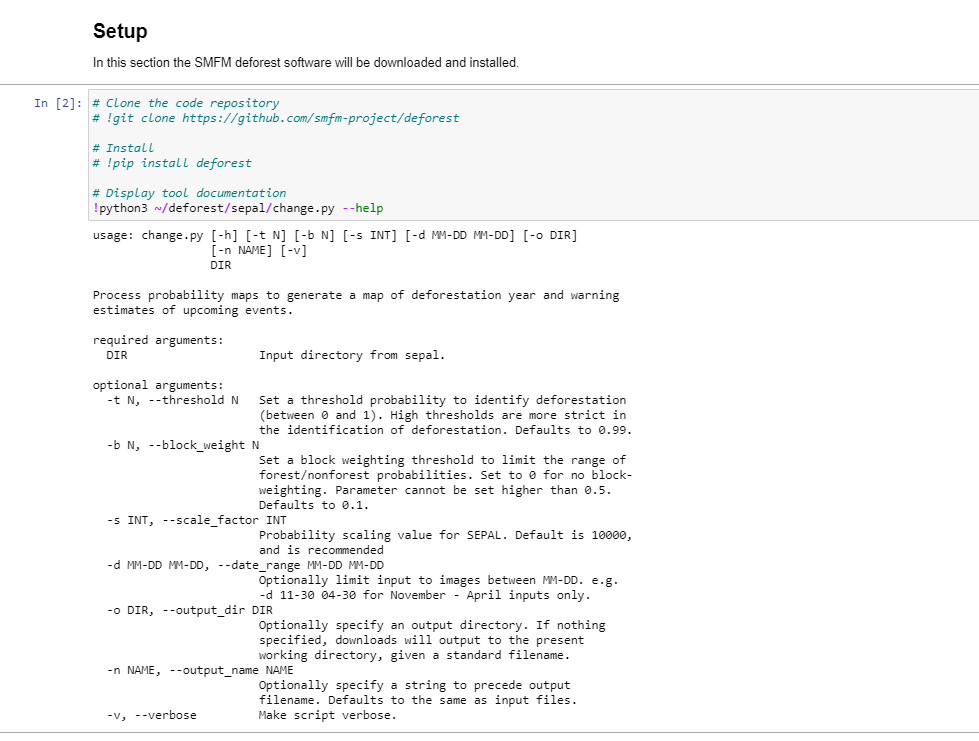
Click and run the first cell under the Setup header. This cell runs two commands: the first installs the deforest Python module and the second runs the –help switch to display some documentation on running the tool.
If the help text is output beneath the cell, move onto Step 3. If there is an error, continue to Step 2. The error message might say:
` python3: can't open file '/home/username/deforest/sepal/change.py': [Errno 2] No such file or directory `
Successful setup.#
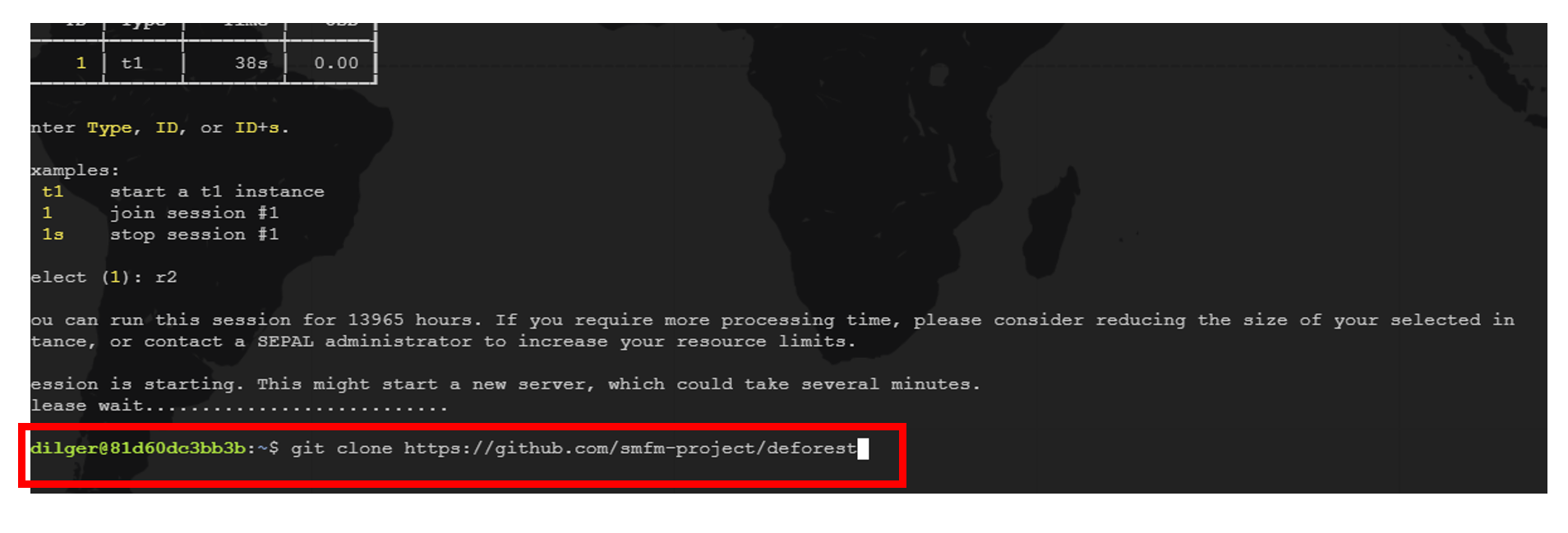
Install the package via the SEPAL Terminal.
Go to your SEPAL Terminal.
Enter 1 to access the terminal of Session 1. You can think of a session as an instance of a virtual machine that is connected to your SEPAL account.
Clone the Deforest GitHub repository to your SEPAL account.
git clone https://github.com/smfm-project/deforestReturn to the SMFM notebook and repeat Step 1.
Once you have successfully set up the tool, take a moment to read through the help document of the Deforest tool that is output below the Jupyter notebook cell you just ran. In the next part, we will explain in more detail some of the parameters.
Process the time series#
Processing the time series imagery can be done with a single line of code using the Deforest change.py command line interface.
To use the demo imagery, you do not need to change any of the inputs. However, if you are using a custom time series you will need to make some modifications. To change the command to point to a custom time series of percent forest images you will need to update the path to your time series.
Original:
!python3 ~/deforest/sepal/change.py ~/deforest/sepal/example_data/Time_series_2021-03-24_10-53-03/0/ -o ~/ -n sampleOutput -d 12-01 04-30 -t 0.999 -s 6000 -v
Example path to time series updated:
!python3 ~/deforest/sepal/change.py ~/downloads/PATH_TO_TIME_SERIES/0/ -o ~/ -n sampleOutputT -d 12-01 01-08 -t 0.999 -s 6000 -v
Note
By default, the time series should be downloaded to a Downloads folder in your home directory and should have another folder in it named 0.
Parameters
Name |
Switch |
Description |
|---|---|---|
Output location |
-o |
output location where images will be saved to SEPAL account |
Output name |
-n |
Output file name prefix |
Date range |
-d |
A date-range filter. Dates need to be formatted as ‘-d MM-DD MM-DD’ |
Threshold |
-t |
Set a threshold probability to identify deforestation (between 0 and 1). High thresholds are more strict in the identification of deforestation. Defaults to 0.99. |
Scale |
-s |
Scale inputs by a factor of 6000. In a full-scale run, this should be set to 10000; here it’s used to correct an inadequate classification. |
Verbose |
-v |
Prints information to the console as the tool is run. |
If you would like to use a time frame other than the example, update the date range switch.
Run the Process the time series cell.
By default, the tool is set to use verbose (-v) output. With this option, as each image is processed, a message will be printed to inform us of the progress.
- This cell runs two commands:
The first line is running the SMFM Deforest change detection algorithm (change.py).
After processing the images, we print them out to ensure the program runs successfully.
Note
The exclamation mark (!) is used to run commands using the underlying operating system. When we run !ls in the notebook, it is the same as running ls in the terminal.
The output deforestation image will be saved to the home directory of SEPAL account (home/username) by default. If you want to save your images in a different location it can be changed by adding the new path after the -o switch.
Download outputs to local computer (optional).
Navigate to the Files section of your SEPAL account.
Locate the output image to download and click to select it. In this case, the image is named sampleOutput_confirmed.
Select the download icon.
Data visualization#
Now that we have run the deforestation processing chain, we can visualize our output maps. The outputs of the SMFM tool are two images: Confirmed and Warning. We will look at the confirmed image first.
Run the first Data visualization cell of the Jupyter notebook.
If you changed the name of your output file, be sure to update the path on Line 8 for the variable confirmed.
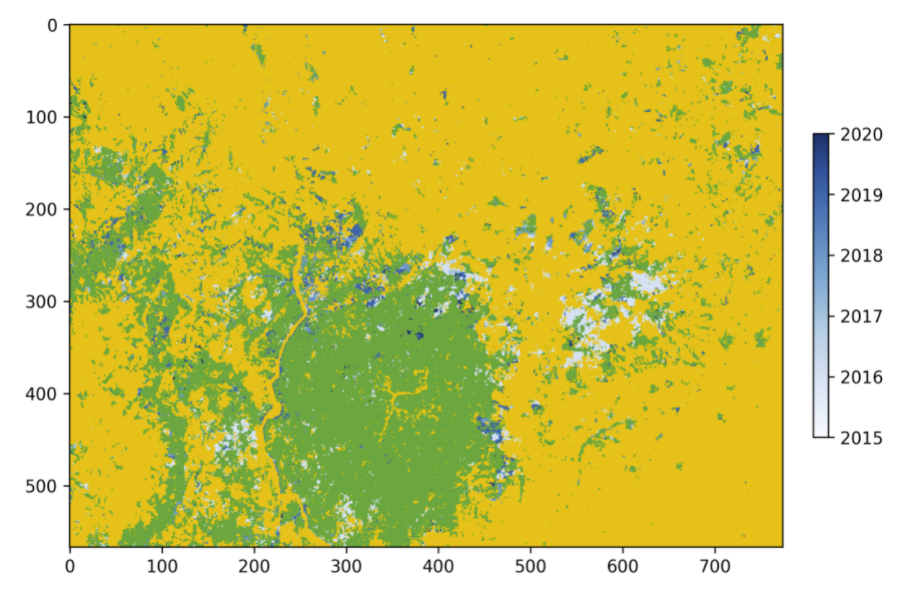
The confirmed image shows the years of change that have been detected in the time series. Stable forest is colored green, non-forest is colored yellow, and the change years colored by a blue gradient.
It is recommended that the user discards the first two to three years of change, or uses a very high-quality forest baseline map to mask out locations that weren’t forest at the start of the time series. This is needed since our input imagery is a forest probability time series which initially considers the landscape as forest.
Next, we will check out the deforest warning output.
Run the second Data visualization cell.
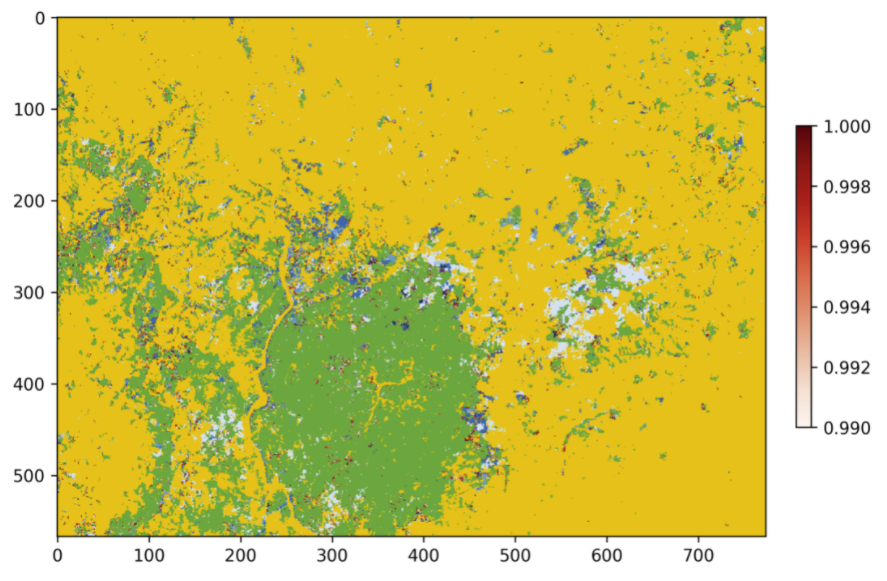
This image shows the combined probability of non-forest existing at the end of our time series in locations that have not yet been flagged as deforested. This can be used to provide information on locations that have not yet reached the threshold for confirmed changes, but are looking likely to be possible.
You can view a demonstration of the above steps in this video.
Additional resources#
Source code: The source code of the Deforest tool and Jupyter notebook can be found in the GitHub repository.
Bug report: in case you notice a bug or have issues using the tool, you can report an issue using the Issues section of the Github repository.
Other approaches to time series analysis#
In this exercise, you will learn more about time series analysis. SEPAL has the BFAST option, described first. We also provide information on TimeSync and LandTrendr, products currently only available outside of SEPAL and CEO.
TimeSync integration is coming to CEO in 2021.
Objectives:
learn the basics of BFAST explorer in SEPAL; and
learn about time series analysis options outside of SEPAL.
Prerequisite:
SEPAL account
BFAST Explorer#
Breaks For Additive Seasonal and Trend (BFAST) is a change detection algorithm for time series which detects and characterizes changes. BFAST integrates the decomposition of time series into trend, seasonal, and remainder components with methods for detecting change within time series. BFAST iteratively estimates the time and number of changes, and characterizes change by its magnitude and direction (Verbesselt et al., 2009).
BFAST Explorer is a Shiny app, developed using R and Python, designed for the analysis of Landsat surface reflectance (SR) time series pixel data. Three change detection algorithms - bfastmonitor, bfast01 and bfast - are used in order to investigate temporal changes in trend and seasonal components via breakpoint detection.
More information can be found online at http://bfast.r-forge.r-project.org. If you encounter any bugs, please send a message to or create an issue on the GitHub page.
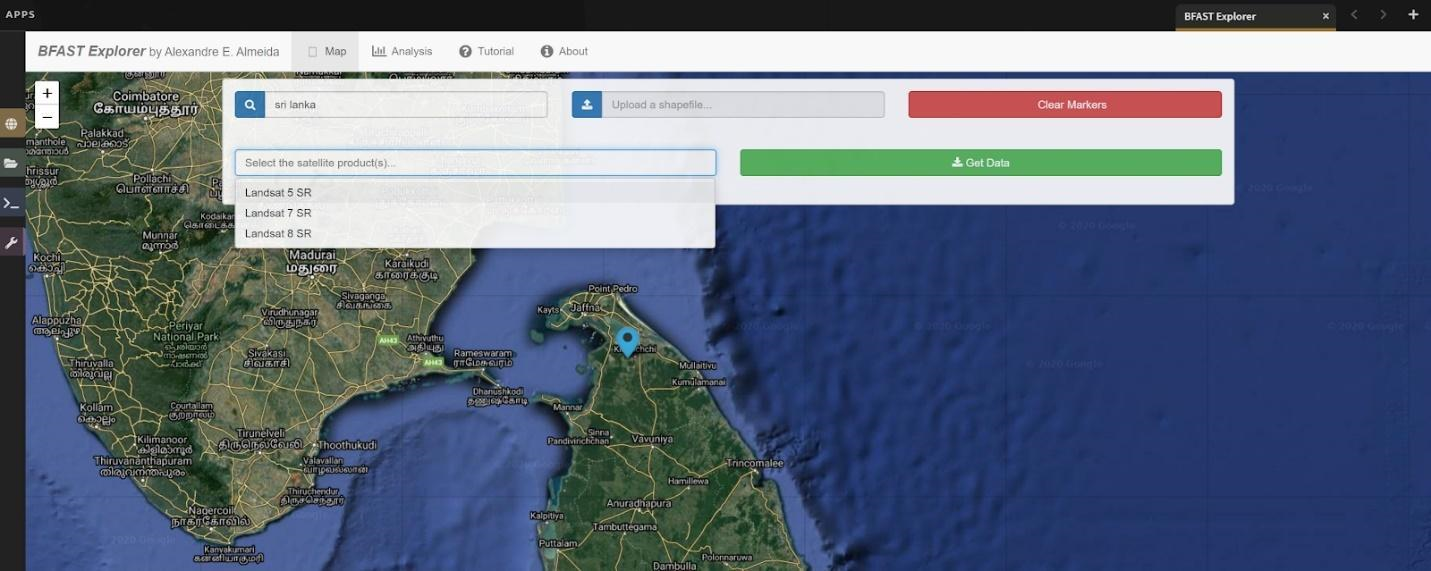
Go to the Apps menu by selecting the wrench icon. Then, enter “BFAST” into the search field and select BFAST Explorer.
Find a location on the map that you would like to run BFAST on. Select a location to drop a marker, and then click the marker to select it. Select Landsat 8 SR from the Select satellite products dropdown menu. Select Get Data (note: it may take a moment to download all of the data for the point).
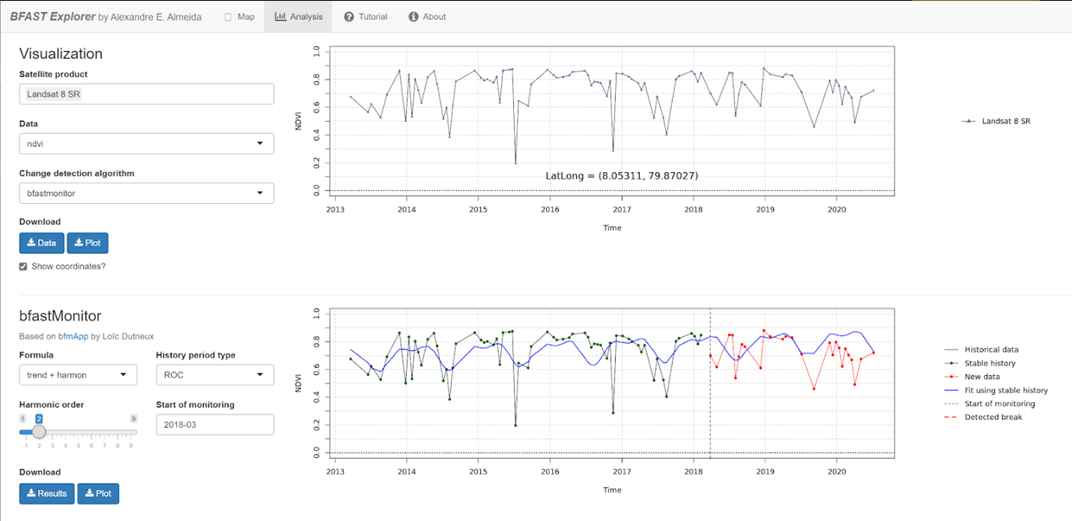
Select the Analysis button (at the top next to the Map button).
Satellite product: Add your satellite data by selecting them from the Satellite products dropdown menu.
Data: The data to apply the BFAST algorithm to and plot. There are options for each band available as well as indices, such as NDVI, EVI, and NDMI. Select ndvi.
Change detection algorithm: Holds three options of BFAST to calculate for the data series.
Bfastmonitor: Monitoring the first break at the end of the time series.
Bfast01: Checking for one major break in the time series.
Bfast: Time series decomposition and multiple breakpoint detection in trend and seasonal components.
Each BFAST algorithm methodology has characteristics which affect when and why you may choose one over the other. For instance, if the goal of an analysis is to monitor when the last time change occurred in a forest, then Bfastmonitor would be an appropriate choice. Bfast01 may be a good selection when trying to identify if a large disturbance event has occurred, and the full Bfast algorithm may be a good choice if there are multiple times in the time series when change has occurred.
Select bfastmonitor as the algorithm.
You can explore different bands, such as spectral bands like b1, along with the different algorithms.
You can download all the time series data by selecting the blue Data button. All the data will be downloaded as a .csv file, ordered by the acquisition date.
You can also download the time series plot as an image by selecting the blue Plot button. A window will appear offering some raster (.jpeg, .png) and a vectorial (.svg) image output formats.
Note
The black and white flashing is normal.
TimeSync and LandTrendr#
Here we will briefly review TimeSync and LandTrendr, two options available outside of SEPAL that may be useful to you in the future. It is outside of the scope of this manual to cover them in detail, but if you’re interested in learning more we’ve provided links to additional resources.
TimeSync#
TimeSync was created by Oregon State University, Pacific Northwest Research Station, the Forest Service Department of Agriculture, and the USFS Remote Sensing Applications Center. From the TimeSync User manual for Version 3:
“TimeSync is an application that allows researchers and managers to characterize and quantify disturbance and landscape change by facilitating plot-level interpretation of Landsat time series stacks of imagery (a plot is commonly one Landsat pixel). TimeSync was created in response to research and management needs for time series visualization tools, fueled by rapid global change affecting ecosystems, major advances in remote sensing technologies and theory, and increased availability and use of remotely sensed imagery and data products…”
TimeSync is a Landsat time series visualization tool (both as a web application and for desktops) that can be used to:
characterize the quality of land cover map products derived from Landsat time series;
derive independent plot-based estimates of change, including viewing change over time and estimating rates of change;
validate change maps; and
explore the value of Landsat time series for understanding and visualizing change on the Earth’s surface.
TimeSync is a tool that researchers and managers can use to validate remotely sensed change data products and generate independent estimates of change and disturbance rates from remotely sensed imagery. TimeSync requires basic visual interpretation skills, such as aerial photo interpretation and Landsat satellite image interpretation.”
Here is an example output from TimeSync’s introduction materials:
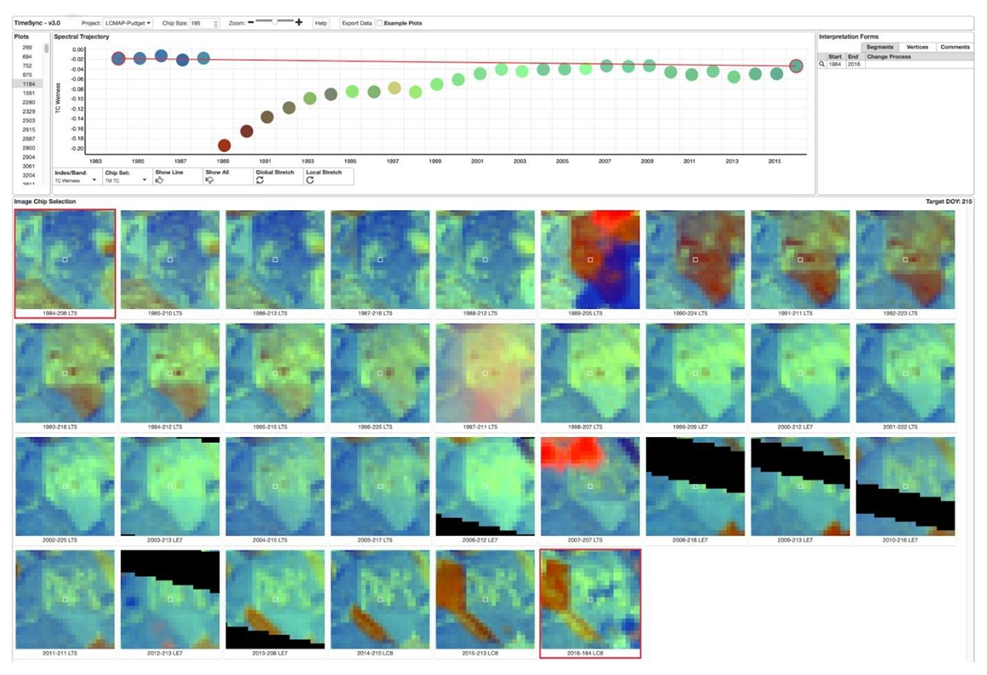
For more information on TimeSync, including an online tutorial (for Version 2), see https://www.timesync.forestry.oregonstate.edu/tutorial.html. You can register for an account and work through an online tutorial with examples and watch a recorded TimeSync training session. You can also find the manual for Version 3 at http://timesync.forestry.oregonstate.edu/training/TimeSync_V3_UserManual_doc.pdf, and an introductory presentation here: https://timesync.forestry.oregonstate.edu/training/TimeSync_V3_UserManual_presentation.pdf.
LandTrendr#
LandTrendr (LT) has similar functionality to TimeSync, but runs in GEE. It was created by Dr. Robert Kennedy’s lab with funding from the US Forest Service Landscape Change Monitoring System, the NASA Carbon Monitoring System, a Google Foundation grant, and the US National Park Service Cooperative Agreement. Recent contributors include David Miller, Jamie Perkins, Tara Larrue, Sam Pecoraro and Bahareh Sanaie (Department of Earth and Environment, Boston University). Foundational contributors include Zhiqiang Yang and Justin Braaten in the Laboratory for Applications of Remote Sensing in Ecology located at Oregon State University and the USDA Forest Service’s Pacific Northwest Research Station.
From Kennedy, R.E., Yang, Z., Gorelick, N., Braaten, J., Cavalcante, L., Cohen, W.B., Healey, S. (2018). Implementation of the LandTrendr Algorithm on Google Earth Engine. Remote Sensing, 10: 691:
“LandTrendr (LT) is a set of spectral-temporal segmentation algorithms that are useful for change detection in a time series of moderate resolution satellite imagery (primarily Landsat) and for generating trajectory-based spectral time series data largely absent of inter-annual signal noise. LT was originally implemented in IDL (Interactive Data Language), but with the help of engineers at Google, it has been ported to the GEE platform. The GEE framework nearly eliminates the onerous data management and image-pre-processing aspects of the IDL implementation. It is also light-years faster than the IDL implementation, where computing time is measured in minutes instead of days.”
From LandTrendr’s documentation, the following figure shows an example output in the GUI. However, LandTrendr has significant non-GUI data analysis capabilities (for a comprehensive guide to running LT in GEE, see https://emapr.GitHub.io/LT-GEE/landtrendr.html).
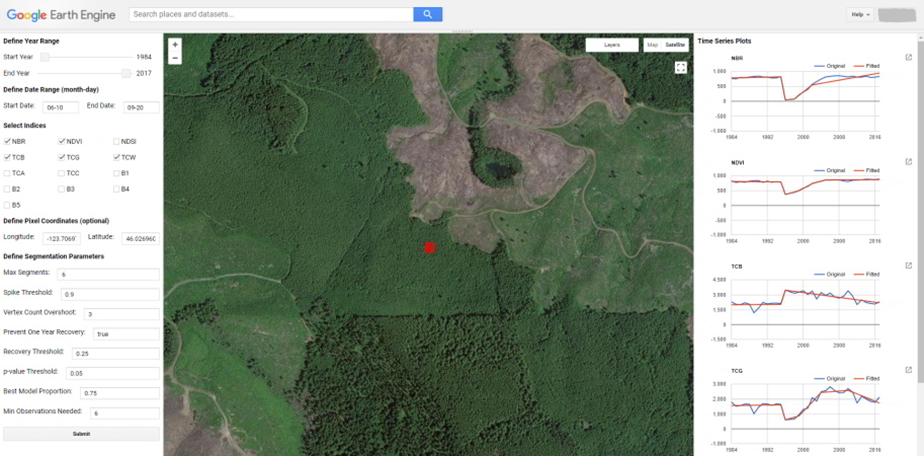
Sample-based estimation of area and accuracy#
Once you have either a land use/land cover (LULC) map (Module 2) or a change detection map (Module 3), the next step is to estimate the area within each LULC type or change type and the error associated with your map (the current module). All maps have errors (e.g. model output errors from pixels mixing or input data noise). Our objective is to create unbiased estimates of the area for each mapped category.
To do this, we will use sample-based estimations of area and error instead of pixel-counting approaches, which simply sum the area belonging to each different class. However, this doesn’t account for classification errors (e.g. the probability that a pixel classified as wetland should be open water). Therefore, the pixel-counting approach provides no quantification of sampling errors and no assurance that estimates are unbiased or that uncertainties are reduced (Stehman, 2005; GFOI, 2016).
Sample-based estimations of area and error create estimations of errors in pixel classification and use this to inform estimations of area. Therefore, sample-based estimations abide by the IPCC General Guidelines (2006) that estimates should not be over- or under- estimates, and that uncertainty should be reduced as much as practically possible. For more information on the theory behind choosing sample-based estimations of area and error over pixel-counting approaches, see the following resources:
Gallego, FJ. 2004. Remote sensing and land cover area estimation. International Journal of Remote Sensing, 25(15): 3019-3047, DOI: 10.1080/01431160310001619607
GFOI. 2016. Integration of remote-sensing and ground-based observations for estimation of emissions and removals of greenhouse gases in forests: Methods and Guidance from the Global Forest Observations Initiative, Edition 2.0. Rome, FAO.
GOFC-GOLD. 2016. A sourcebook of methods and procedures for monitoring and reporting anthropogenic greenhouse gas emissions and removals associated with deforestation, gains and losses of carbon stocks in forests remaining forests, and forestation. GOFC-GOLD Report version COP22-1. The Netherlands, GOFC-GOLD Land Cover Project Office, Wageningen University.
IPCC. 2006. Guidelines for national greenhouse gas inventories. Volume 4: Agriculture, Forestry and Other Land Use. http://www.ipcc-nggip.iges.or.jp/public/2006gl/vol4.html
REDD Compass: https://www.reddcompass.org
There are four steps to sample-based estimation of area and accuracy. First, you will use the different classes in your LULC or change detection map to create a stratified sampling design in SEPAL using the Stratified Area Estimator (SAE) - Design tool (Exercise 4.1). Then you will revisit your response design and labelling protocols to use with data collection in CEO (Exercise 4.2). Finally, you will use data generated in CEO (Exercise 4.3) to calculate the sample-based estimates in SEPAL, using the Stratified Area Estimator-Analysis tool (Exercise 4.4). This tool quantifies the agreement between the validation reference points and the map product, providing information on how well the class locations were predicted by the Random forest classifier.
This process will provide two important outputs. First, you will have estimates of the area for each LULC or change type. Second, you will have a table that describes the accuracy for each LUC or change type. This is often called a confusion matrix. These may be final products for your projects. However, if you decide that your map is not accurate enough, this information can be fed back into the classification or change detection algorithms to improve your model.
This module takes approximately three hours to complete.
Sample design and stratification#
Stratified random sampling is an easy-to-use, easy-to-understand, and well-supported sampling design (for more information, see Olofsson et al. 2014. Good practices for assessing accuracy and estimating area of land change. Remote Sensing of Environment, 148: 42-57). With stratified random sampling, each class (e.g. land use, land cover, change type) is treated as a strata. Then, a sample is randomly taken from each sample, either in proportion to area, in proportion to expected variance, or in equal numbers across strata.
We will use the SEPAL SAE-Design tool. You will upload your classified map and set some basic parameters, then the SAE-Design tool will generate a set of stratified random points that are placed in each of the different land cover classes represented in your map. The number of points in each class will be scaled to the area each class covers in the map. The total sample size – the number of points used to validate the map – will depend on your expected overall accuracy. Be sure to log these choices as part of your documentation (Module 5).
Uploading files to SEPAL#
If your classification is not stored in SEPAL (e.g. a classification in GEE or a classification created through CODED), you will need to upload it to SEPAL in order to use SEPAL’s Stratified random sample tool. Several options are described in Exchange files with SEPAL.
Creating a stratified random sample#
We will use SEPAL to create a stratified random sample. To begin, you can use the test dataset available in SEPAL or you can use a raster of your classification loaded into SEPAL.
If you have a large area that you are stratifying, first increase the size of your instance (see Introduction to SEPAL).
A well-prepared sample can provide a robust estimate of the parameters of interest for the population (e.g. percent forest cover). The goal of a sample is to provide an unbiased estimate of some population measure (e.g. proportion of area), with the smallest variance possible, given constraints including resource availability. Two things to think about for sample design are: do you have a probability-based sample design? That is, does every sample location have some probability of being sampled? And second, is it geographically balanced? That is, are all regions in the study area represented? These factors are required for the standard operating procedures when reporting for REDD+.
These directions will provide a stratified random sample of the proper sampling size.
First, go to https://sepal.io and sign in.
Select the Apps button (purple wrench). Enter stratified into the search bar or scroll through the different process apps to find Stratified Area Estimator - Design.
Select Stratified Area Estimator - Design. Note that loading the tool takes a few minutes.
Tip
Sometimes the tool fails to load properly (none of the text loads) as seen below. In this case, please close the tab and repeat the steps presented above.
When the tool loads properly, it will look like the image below. Read some of the information on the Introduction page to acquaint yourself with the tool.
On the Introduction page, you can change the language from English to French or Spanish.
The Description, Background, and How to use the tool panes provide more information about the tool.
The Reference and Documents pane provides links to other information about stratified sampling, such as REDD Compass.
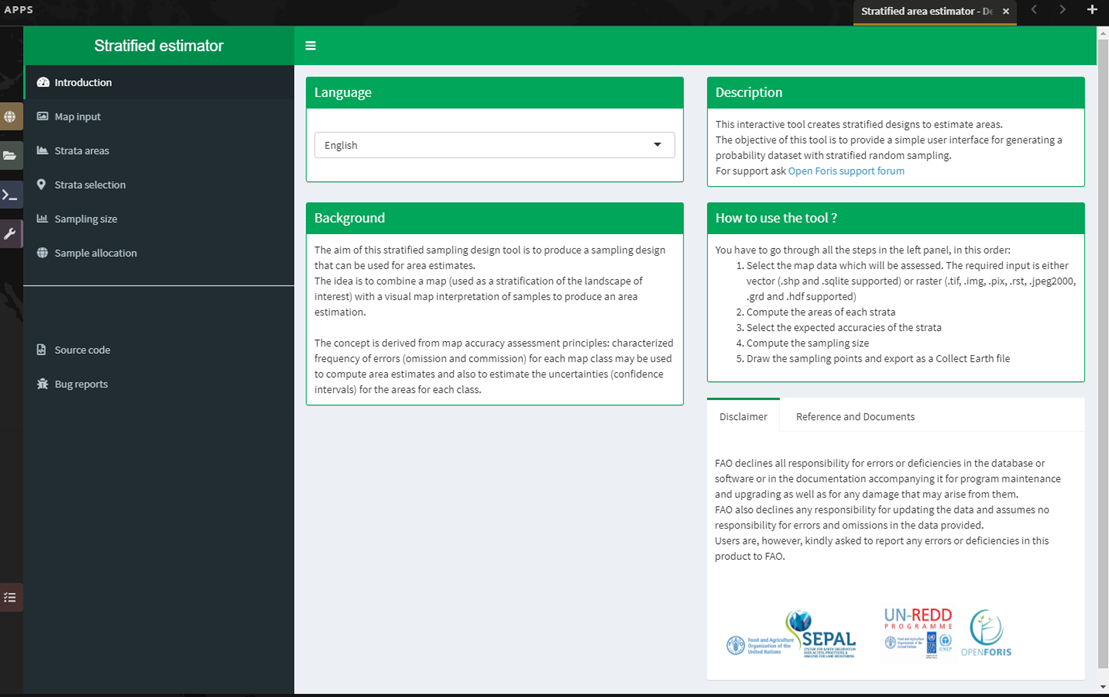
The steps necessary to design the stratified area estimator are located on the left side of the screen and they need to be completed sequentially from top to bottom.
Select Map input on the left side of the screen.
For this exercise, we’ll use the classification from Module 2.
Note
You can substitute another classification, such as the change detection classification created in Module 3, if desired.
In the Data type section, select Input.
In the Browse window that opens, go to the Module 2 dataset and select it. Then choose Select.
Tip
Note that the Output folder section shows you where in your SEPAL workspace all files generated from this exercise will be saved.
Next, select Strata areas on the left side of the screen. In the Area calculation section, select OFT (OFT refers to the Open Foris Geospatial Toolkit). R is slower but avoids some errors that arise with OFT.
Attention
If you choose to use OFT, it will return values for the map that are incorrect in the event that your map was stored in certain formats (e.g. signed 8 bit). If this is the case, use the R option and it will work correctly. If using OFT, always compare the Display map with the Legend labeling values returned to make sure they match.
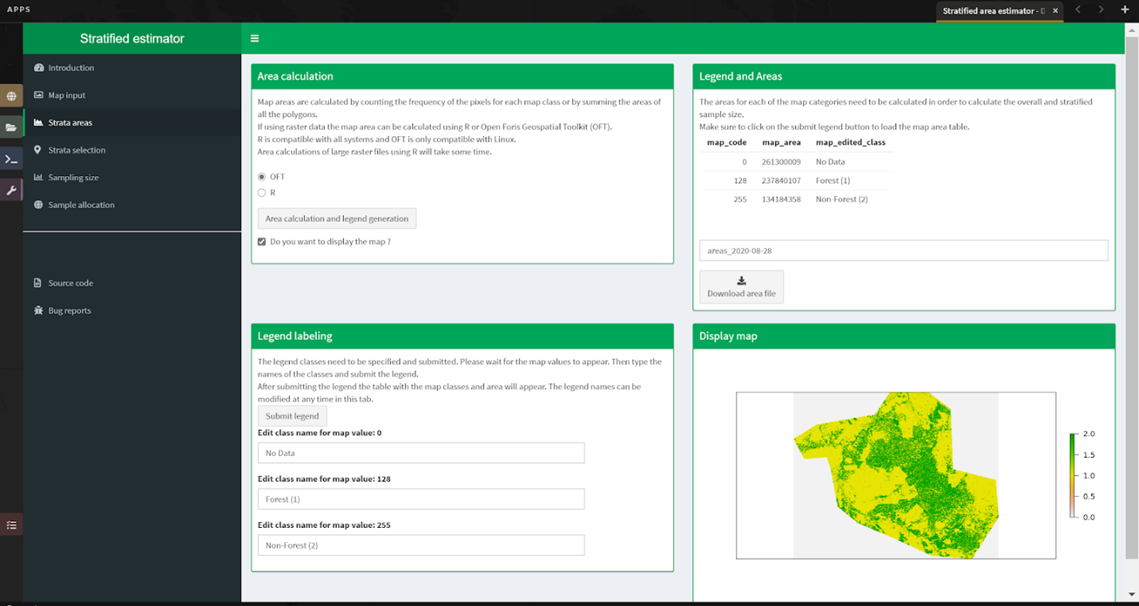
The Do you want to display the map checkbox allows you to display your geotiff under “Display map”.
Note
The colors displayed in the SAE-Design tool in this section may be different than what you see elsewhere. Additionally, if your ‘no data’ class is 0, the tool will color this as well.
Select the Area calculation and legend generation button. This will take a few minutes to run. After it finishes, notice that it has updated the Legend labeling section of the page.
Next, you will need to adjust the class names in the Legend labeling section. Type in the following class names in place of the numeric codes for your Amazon:
0 = No Data
1 = Forest
2 = Non-forest
Now select Submit Legend. The Legend and Areas section will now be populated with the map code, map area and edited class name.
You can now Rename and Download the area file if you would like; it will save automatically to your SEPAL workspace.
When you’re done, click on Strata selection in the left pane.
Now you need to specify the expected accuracies. You will do this for each class. Get more information by selecting the plus button to the right of the box that says What are the expected accuracies?.
Specifying the expected user accuracy helps the program determine which classes might need more points relative to their area.
Some classes are easier to identify, including common classes and classes with clear identifiers like buildings.
Classes that are hard to identify include rare classes and classes that look very similar to one another. Having more classes with low confidence will increase the sample size. - Select the value for classes with high expected user accuracy with the first slider. This is set to 0.9 by default, and we’ll leave it there. - Then, select the value for classes with low expected user accuracy with the second slider. This is set to 0.7 by default, and we’ll leave it there as well.
Now we need to assign each class to the high or low expected user accuracy group. Think about your forest and non-forest classes. Which do you think should be high confidence? Which should be low confidence? Why?
Select the box under high confidence and assign your high confidence class(es).
Then, select the box under low confidence that appears and assign the corresponding class(es). If you make a mistake, there’s no way to remove the classes. However, just change one of the sliders slightly, move it back, and the class assignments will have been reset.
Attention
For this exercise, please assign both Forest & Non-forest to the high confidence class. If you assign either to the low confidence class, you will not be able to use the CEO-SEPAL bridge in Section 4.2.
DO NOT assign your No data class to either high or low confidence.
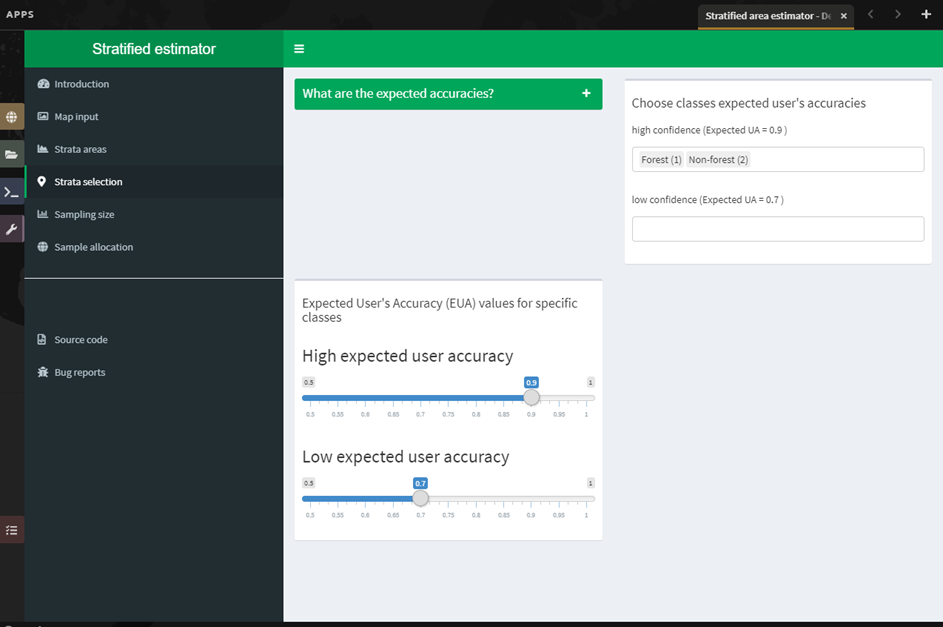
When you’re satisfied, select Sampling size in the left pane.
Now we will calculate the required sample size for each strata. You can select the “+” button to get more information.
First we need to set the standard error of the expected overall accuracy. It is 0.01 by default, however for this exercise we will set it to 0.05.
Note
Note that you can adjust this incrementally with the up/down arrows on the right side of the parameter.
Then determine the Minimum sample size per strata. By default, it is 100. For the purposes of this test we will set it to 20, but in practice this should be higher.
Note
You can also check the Do you want to modify the sampling size box.
While SEPAL automatically saves this file, you can edit the name of the file and download a .csv file with the sample design. The file will contain the table shown above with some additional calculations.
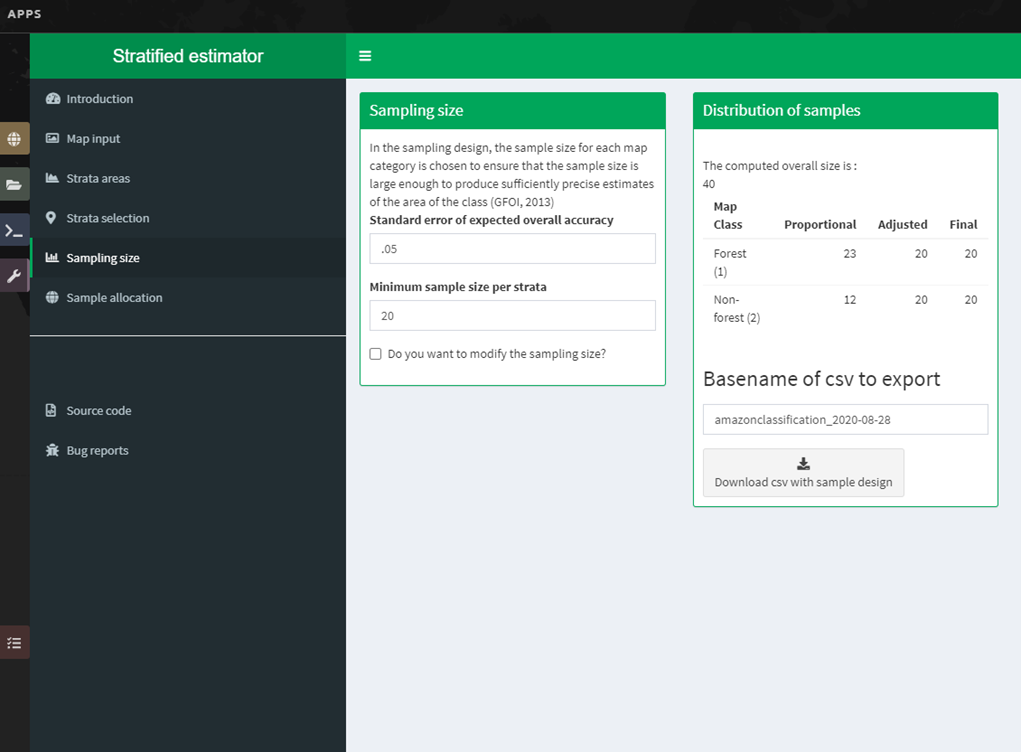
When you’re ready, select Sample allocation on the left. The final step will select the random points to sample.
Select Generate sampling points and wait until the Progress bar in the lower-right finishes. Depending on your map, this may take some time. A map will pop up showing the sample points. You can pan around or zoom in/out within the sample points map. The resulting distribution of samples should look similar to the below image.
Note
These values will vary depending on your map and the standard error of expected overall accuracy you set.
Tip
Sometimes this step fails, no download button will appear, and you will need to refresh the page and restart the process.
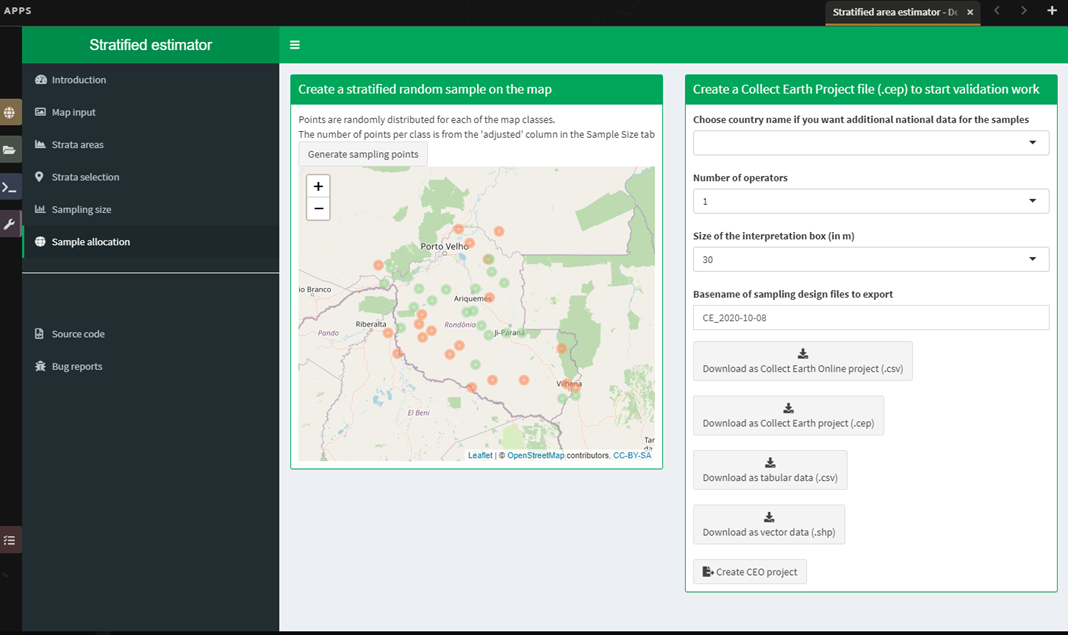
Now fill out the four fields to the right. You can add additional data by specifying which country the map is in. Here, leave the Choose your country name… section blank. Specify the number of operators, or people who will be doing the classification. Here, leave it set to 1. For CEO, this might be the number of users you think your project will have. The size of the interpretation box depends on your data and corresponds to CEO’s sample plot. This value should be set to the spatial resolution of the imagery you classified (Landsat = 30 m). Here, leave it at 30 m.
Note
When should you use CEO, and when should you use the CEO-SEPAL bridge? In general, the CEO-SEPAL bridge should only be used for fairly simple use cases. More specifically, CEO-SEPAL is a great option when you have only high-confidence categories, have a relatively small number of points, when you will collect the data yourself, and when the built-in questions about your data points suffice. For other situations, you will want to create a CEO project. Creating a CEO project through the collect.earth website is a better option when you have low-confidence categories, a larger number of points in your sample, when you want to use specific validation imagery, when multiple people will collect data and you need to track who is collecting data, and when you need more complex or custom questions about your data points.
If you would like to create a project via CEO, select Download .csv and follow the steps in Section 4.1.3 below. After following these directions, proceed to Section 4.2.
Attention
We highly recommend using this approach, and we will demonstrate it in this manual.
To create a project via the CEO-SEPAL bridge, select Create CEO project. This will create a CEO project via the CEO-SEPAL bridge. This process will take a few minutes and you should see text and completion bars in the lower right as calculations happen. Copy and paste the link into your browser window when it appears.
Tip
Be sure to save this link somewhere so you can reference it later.
Attention
You must be logged out of CEO for this pathway to work.
When the project has been created, skip to Section 4.2.
You can download a .shp file to examine your points in QGIS, ArcGIS or another GIS program. You can also create a CEO project using a .shp file, however that is outside of the scope of this article. Directions can be found in the institutional manual at https://collect.earth/support.
Creating a CEO project via .csv#
For projects with large sample sizes, where you want to have multiple people collecting validation data or where you want to use specific validation imagery, you will want to create a project through CEO rather than through the CEO-SEPAL bridge. (Note that the total number of plots you want to sample using a .csv file must be 50000 or less. If you have more plots, break it into multiple projects.)
Make sure you have downloaded the .csv file of your stratified random sample plots (Section 4.1.2). Open your downloaded .csv file in Excel or the spreadsheet programme of your choice. First, make sure that your data doesn’t contain a strata of “no data”. This can occur if your classification isn’t a perfect rectangle, as seen in this example of Nepal (the red circles are samples that the tool created in the “no data” area).
Tip
If you have “no data” rows, return to the SEPAL stratified estimator, and be sure to not include your no data class in the strata selection step.
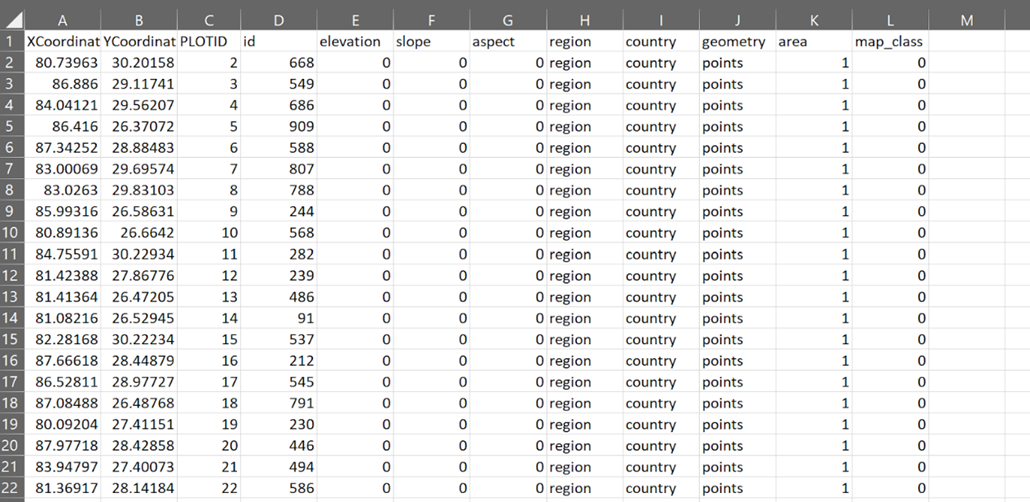
Right now, your stratification is grouped by land cover type (map_class column). To reduce the human tendency to use the order of the plots to help identify them (e.g. knowing the first 100 plots were classified forest, so being more likely to verify them as forest instead of determining if that is correct), we suggest first randomizing the order of the rows. To do this, select the Sort & Filter button in Excel.
Next, Sort on the id field by value, either smallest to largest or largest to smallest.
Now we need to add the correct columns for CEO. Remember that latitude is the Y axis and longitude is the X axis. For CEO, the first three columns must be in the following order: longitude, latitude, plotid. The spelling and order matter. If they are wrong CEO will not work correctly.
Rename “id” to PLOTID. You can also add a new PLOTID field by creating a new column labeled PLOTID, and fill it with values 1-(number of rows).
Rename the ‘XCoordinate’ column to ‘LONG’ or ‘LONGITUDE’.
Rename the ‘YCoordinate’ column to ‘LAT’ or ‘LATITUDE’.
Reorder the columns in Excel so that LAT, LONG, PLOTID are the first three columns (in that order).
Save your updated .csv file, making sure you save it as a .csv and not as an .xlsk file.
Go to collect.earth. Sign in to your CEO account. If you’re already the administrator of an institution, go to your institution’s landing page by typing in the institution’s name and then selecting the Visit button.
Tip
Creating a project in CEO requires you to be the administrator of an institution. If you’re not an admin, you can create a new institution. Select Create new institution from the homepage, then fill out the form & select Create institution.
When you’re on the institution’s page, select the Create new project button. This will go to the Create project interface. We’ll now talk about what each of the sections on this page does. For more information, please see the institutional manual available on the collect.earth support page at https://collect.earth/support.
TEMPLATE: This section is used to copy all of the information — including project info, area and sampling design — from an existing published project to a new project.
This is useful if you have an existing project you want to duplicate for another year or location, or if you’re iterating through project design. You can use a published or closed project from your institution or another institutions’ public project.
The project id is found in the URL when you’re on the data collection page for the project.
PROJECT INFO: Under Project info, enter the project’s Name and Description.
The Name should be short and will be displayed on the Home page as well as the project’s Data Collection page.
You should keep the Description short but informative.
The Privacy Level radio button changes who can view your project, contribute to data collection, and whether admins from your institution or others creating new projects can use your project as a template.
AOI: Determines where sample plots will be drawn from for your project. This is the first step in specifying a sampling design for your project. There are two main approaches for specifying an AOI and sampling design:
First, using CEO’s built in system.
Second, creating a sample in another program and importing it into CEO, which what we have done. You will specify the AOI in the sample design step instead.
You should choose your Basemap source, which will be the default imagery that the user sees.
If needed, check the box for any additional imagery you would like to add (optional).
Sample Plot Design: Here, select the radio button next to .csv.
Select Upload and upload the .csv file of your stratified random sample. Note that the number of plots you want to sample must be 5000 or less.
Select if you would like round or square plots, and specify the size. For example, you might specify square plots of 30 m width in order to match Landsat grid size.
Sample Point Design: Under the Sample Design header, it is really determining the sample point design within each sample plot.
You can choose Random or Gridded, as well as how many samples per plot or the sample resolution respectively. You can also choose to have one central point.
Using CEO’s built-in system, the maximum number of sample points per plot is 200. The maximum total number of sample points for the project across all plots is 50000.
Survey Design: This is where you design the questions that your data collectors/photo interpreters will answer for each of your survey plots. Each question creates a column of data. This raw data facilitates calculating key metrics and indicators and contributes to fulfilling your project goals.
Survey Cards are the basic unit of organization. Each survey card creates a page of questions on the Data Collection interface.
The basic workflow is: Create a new top-level question (new survey card), then populate answers. Create any child questions and answers, then move to the next top-level question (new survey card). Repeat until all questions have been asked.
You can ask multiple types of questions (including the button—text questions from the simple interface). You can also add survey rules in the Survey Rules Design pane.
Broadly, there are four question types and three data types. They are combined into ten different component types.
The four question types are:
Button: This creates clickable buttons, allowing users to select one out of many answers for each sample point.
Input: Allows users to enter answers in the box provided. The answer text provided by the project creator becomes the default answer.
Radio button: This creates radio buttons, allowing users to select one out of many answers for each sample point.
Dropdown: Allows users to select from a list of answers.
The three data types allowed are:
Boolean: Use this when you have two options for a question (yes/no).
Text: Use this when you have multiple options that are text strings. They may include letters, numbers or symbols.
Number: Use this when you have multiple options that are numbers, which do not contain letters or symbols.
First, type in your question in the New question box, such as Is this forest or non-forest?
Then select Add survey question.
A new survey card (Survey Card Number 1) will pop up with your question in it.
You can now add answers.
Create one answer for each of your land use types. Here we will use 1 and **2 to match Forest and Non-forest in our classification. Be sure to include all of your land use types.
Note that the Stratified Area Estimator–Analysis only accepts numeric values for the land use types. If you would like to use human-readable text values (e.g. Forest instead of 1), you must follow the directions in Section 4.3.2.
You can add additional survey questions, if you’d like to experiment. An example of two survey cards is shown below.
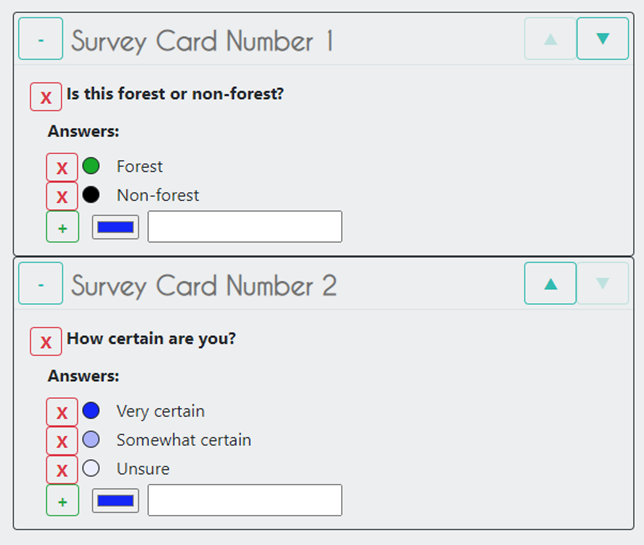
When you’re done, select Create Project. If you’re successful, you’ll see the Review project pane. The Project AOI will now show the location of a subset of your plots (a maximum number can be displayed).
Not shown are the Plot Review and Sample Design, which show a summary of the choices you made, or the .csv and .shp files you uploaded. Survey Review shows all the Survey Cards you created, along with the corresponding Component Type, Rules, and Answers. At this point, your project has been created, but it has not been published so that other users can see it.
You can either select Publish Project or Configure Geo-Dash. The option to Configure Geo-Dash will be available after you publish your project as well. For now, let’s select Configure Geo-Dash. A new window or tab will open and you’ll now see the blank Geo-Dash configuration page.
Geo-Dash is a dashboard that opens in a second window when users begin to analyse sample plots. Geo-Dash provides users with additional information to help them interpret the imagery and better classify sample points and plots. The Geo-Dash tab can be customized to show information such as NDVI time series, forest degradation tools, additional imagery and digital elevation data. If you select Geo-Dash Help, you’ll access information about all of the Geo-Dash widgets. This information is also in the CEO user manual. Add any widgets that you would like for your project.
For example, you can add a NDVI widget by following these steps:
Click on Add Widget, then select the Image Collection type.
Select your Basemap imagery.
Now you’ll see the Data dropdown menu. Select NDVI in this menu.
Now you’ll see the Title.
Give your widget a title that describes the data.
Select the date range using the calendar widgets or by entering it.
Select Create.
You can now move the widget by clicking and dragging from the centre and resizing it by clicking and dragging the lower-right corner. When you’re done adding widgets, close the Geo-Dash window.
On the Project review page, select Publish project. Collect Earth will ask you to confirm; select OK. You can now visit your project from your institution’s page and start collecting data!
More detailed instructions, including descriptions of useful options, can be found in the manuals for CEO: https://collect.earth/support.
Data collection with data quality management approaches#
Once you have created a stratified random sample, you will use CEO (or the CEO-SEPAL tool) to visually interpret the land cover at the sample locations using a suitable source of reference data (often remote sensing data). These visual interpretations will then inform the area and error estimation (Section 4.3). However, to ensure accurate human interpretation of land cover, you will need to adopt data quality management approaches. In this exercise, you will check your classification design (Section 4.2.1), plan your data collection (Section 4.2.2), collect your data (Section 4.2.3) and set up quality management (Section 4.2.4 and Section 4.2.5).
The reason for this focus on data quality is simple: area and error estimates are based on the human interpreter’s labeling of the sample; therefore, it is important that the labels are correct. Some recommend that three interpreters examine each unit independently, while other projects just have a sub-sample of the data points cross-checked by another interpreter. In Section 4.2.4 and Section 4.2.5, you will consider this and design a quality assurance plan that meets the needs and budgets of your specific mapping projects and management needs.
Much of this information is based on SOPs developed by Till Neeff at FAO for global application. Following these exercises will help you abide by these guidelines and meet these standards of quality for the data collected.
Objectives:
understand how to set up a successful verification project;
collect land cover verification data about each of your sample points; and
create quality management protocols for your verification project.
Prerequisites:
stratified random sample based on your image classification from Section 4.1; and
CEO-SEPAL project initiated in Section 4.1.
Specify a classification scheme#
Classification scheme is the name used to describe the land cover/land use classes adopted. It should cover all the possible classes that occur in interest. Just as when you are creating training data for your classification, you will need to have a response design with consistent labeling protocols when collecting data for your area and error estimates.
If you have already created a response design in Module 2, you should use that.
If you have not created a response design for the classification you are now evaluating, please refer to Exercise 2.1 to create a classification scheme. Note that if your classification was trained using training points that differ substantially from your classification scheme, you may need to collect new training data and re-run your classification.
As a reminder, our classification used to classify our Forest/Non-forest land cover map was as follows:
![digraph process {
lc [label="Land cover", shape=box];
f [label="Forest", shape=box, style="filled" color="darkgreen"];
nf [label="Non forest", shape=box, style="filled", color="grey"];
lc -> f;
lc -> nf;
}](../_images/graphviz-e8d15b8835714e2af6731405ed130bd5d366de47.png)
We defined Forest as an area with over 70 percent tree cover. We defined Non-forest as areas with less than 70 percent tree cover. This captured land covers including urban areas, water and agricultural fields.
Planning data collection#
Now that we have the framework for the procedure for data collection with quality in mind, we can work through what it would be like setting up the process for a team. Data collection efforts require planning, particularly for large efforts with many interpreters involved. We will discuss these planning aspects here.
In this part, you will assume the role of a coordinator and an interpreter for a small team working to validate the land cover classification from Module 2. A coordinator is responsible for organizing the team and tracking compliance information; an interpreter is responsible for collecting data.
Identify the reference data sources#
Ideally, you would have plots revisited in the field. However, this is rarely attainable given limited resources. An alternative is to collect reference observations through careful examination of the sample units using high-resolution satellite data (or moderate-resolution if high-resolution is not available). The more data you have at your disposal, the better.
If you have no additional data, you can use remote sensing data, such as Landsat data, for collecting reference observations, as long as the process to collect the reference data is more accurate than the process used to create the map being evaluated. Careful manual examination can be regarded as being a more accurate process than automated classification.
Consider what additional data you might be able to include in your verification. Do you have access to satellite data at a finer resolution than Landsat? Could you incorporate additional data sets such as stump data or on-the-ground verifications? You might try searching databases, such as https://developers.google.com/earth-engine/dataset.
In CEO, these are the additional data sources that you have added to your CEO project. The CEO-SEPAL bridge uses only the default imagery, which is currently Mapbox Satellite.
Compile a list of your data sources and review it with your interpreters. Recording this information is important for documentation (see Module 5).
Determine level of effort#
Estimate the necessary level of effort for the data collection using the following formula:
Minutes to interpret one sample unit * number of sample units = required level of effort for data collection
If information is available from previous inventories, use that experience to set the value on the time required for assessing sample units from previous experience using the same response design. Otherwise, carry out a test.
For this exercise, consider how long it took you to create your training data in Module 2 and use the formula above to estimate how long it will take to classify all your samples.
Identify data collection participants#
As coordinator, you will identify the persons who may be involved in the data collection. You should set up minimum qualifications for participating in the data collection, such as familiarity with the landscape and previous experience.
What qualifications do you think are important?
What qualifications are essential, and which would be nice to have?
How can you build capacity within your organization for data collection?
As coordinator, you will record names and contact information of all participants in data collection and training.
Here’s a template:
Name |
Contact |
Institution |
Role for data collection |
|---|---|---|---|
Name |
Email address and/or phone number |
Institution name |
Coordinator |
Name |
Email address and/or phone number |
Institution name |
Trainer |
Name |
Email address and/or phone number |
Institution name |
Sample interpretation |
Name |
Email address and/or phone number |
Institution name |
Sample interpretation |
Name |
Email address and/or phone number |
Institution name |
etc. |
And a worked example:
Name |
Contact |
Institution |
Role for data collection |
|---|---|---|---|
Phạm Tuân |
Institute for Collecting Data |
Coordinator |
|
Sally Ride |
Training Specialists Institution |
Trainer |
|
Rodolfo Vela |
Institute for Collecting Data |
Sample interpretation |
|
Yuri Gagarin |
Institute for Collecting Data |
Sample interpretation |
Based on this information, you will decide on the format and modality for the data collection and on a timeline. For example, the format of the data collection can be a mapathon setup where a large group collects the data over a short amount of time or a smaller team that collects the data over long periods. The modality for the data collection concerns where the team collects the data, either in the same location or disparate locations (e.g. in a mapathon, the interpreters could be in the same room interpreting the data). If the data collection is set up in disparate locations, modes of communication should be specified to help improve the consistency in the data interpretation. Multiple remeasurements for all samples is another option.
The logistics manager (if different from the coordinator) will arrange logistics, including space for data collection, sufficient time for data collection and salary arrangements.
With your fictional team (above) and your timeline laid out in the scenario, decide on the format and modality for the data collection and create a timeline.
What other modalities of data collection can you think of?
What are the pros and cons of these modalities?
Organize training and calibration sessions#
As a first step in the data collection, the coordinator and the trainer organize and prepare a training event for the interpreters who have confirmed their participation. The training should cover the following topics as a minimum:
the response design and the interpretation key (detailing location-specific examples from all classes in the classification system with visualization from multiple data sources available);
the software used for the data collection and how to ensure the data management and storage;
the data sources available; and
quality management practices.
Now knowing what to do, consider list items above and briefly fill in details for each topic in another document. Write this as if you were planning a training event before collecting verification data for your forest/non-forest classification. What other topics do you think should be in the training?
The trainer should then implement the training event following these basic principles:
create an environment for active participation, where participants can share questions and opinions;
encourage communication between the interpreters;
record attendance of the interpreters; and
assess the capacity of the interpreters at the end of the training and record the results.
Thinking about these basic principles for a training, briefly write out how you might achieve these goals.
Following the training, the coordinator and the trainer should prepare a report summarizing:
the training actions taken;
the attendance (example below); and
the results of the assessment of capacity.
This information should be documented as part of the decision-making process for the verification (see Module 5).
Name |
Day 1 |
Day N |
|---|---|---|
Interpreter 1 |
present |
present |
Interpreter x |
present |
present |
Distribute and assign sample units to interpreters#
As coordinator, you will decide on a fraction of sample units to be assessed multiple times by all interpreters for cross-checking. Using approximately 2.5 percent of plots for cross-checks is a good starting point. The samples that are duplicated should have a unique identification and/or be recorded in some way.
Note
We will discuss this aspect of quality management in Part 4.
The coordinator should then allocate sample units to interpreters based on some system. Allocation modalities are the modalities by which sample units are allocated to each interpreter (e.g. randomly), following experience in a specific area.
Tip
Answer the following questions: What method might you prefer be used to allocate samples? Why?
The coordinator should use a standardized naming structure to distribute the samples to the interpreters. The coordinator should record the number of sample units the interpreter assigned to assess those samples and the file location in a table like the one below. The naming structure can include metadata such as the date the samples are distributed, the name of the interpreter and the purpose of the data collection. Try preparing a document to distribute the sample units among interpreters like the table below:
Number of sample units |
Interpreter name |
File name |
File archive location |
|---|---|---|---|
X sample units |
Interpreter 1 |
e.g. collection_data_date n[year/month/day] n_version_number.csv |
Link to cloud storage or folder path to repository |
In CEO, multiple interpreters can work on the same project at the same time. This makes it very easy to collect data collaboratively. When you later download the data, each interpreter’s email address will be attached to the point they collected. If you use CEO-SEPAL, you cannot collect this information (as of the date of writing this article).
Collecting data#
After training and sample allocation, it is time to collect data. This can occur in the CEO-SEPAL interface (for smaller projects) or via CEO for larger or multiuser projects. Here, we will demonstrate collecting data in CEO to ensure compliance with SOPs and oversight requiring interpreter names be collected for the points they collect; however, the directions are largely the same for the CEO-SEPAL bridge. How to set up a CEO project is discussed in Part 2 of Exercise 4.1. How to set up a CEO-SEPAL project is discussed at the end of Section 4.1.1.
Data collection by interpreters#
In general, data collection should include the following steps:
When interpreting the samples, use an interpretation key as a guide for assessing different land-use classes and transitions. When possible, consult other interpreters and the coordinator if there are any doubts about the image interpretation.
The coordinator collects the data from all interpreters at defined intervals (intervals can be defined by number of samples or by time intervals) to perform quality assurance procedures, including auxiliary data checks, cold checks and hot checks, as defined in the quality assurance section.
During the data collection, the coordinator organizes regular discussions and group assessment of samples with all the interpreters to ensure a mutual understanding of the interpretation techniques.
Take notes of challenges and limitations during the data collection as well as potential sources of bias during the data collection. If working as part of a team of collectors, pass this information along to the coordinator.
Data collection in CEO#
To collect data in CEO, navigate to the project you created in Section 4.1.2. Your screen should look like this:
Select Go to first plot. This will take you to your first plot. Answer all questions for your first plot by selecting the appropriate answers. If you created multiple questions, you can navigate between questions using the numbers above your question text. Select Save to save your answers and move on to the next plot.
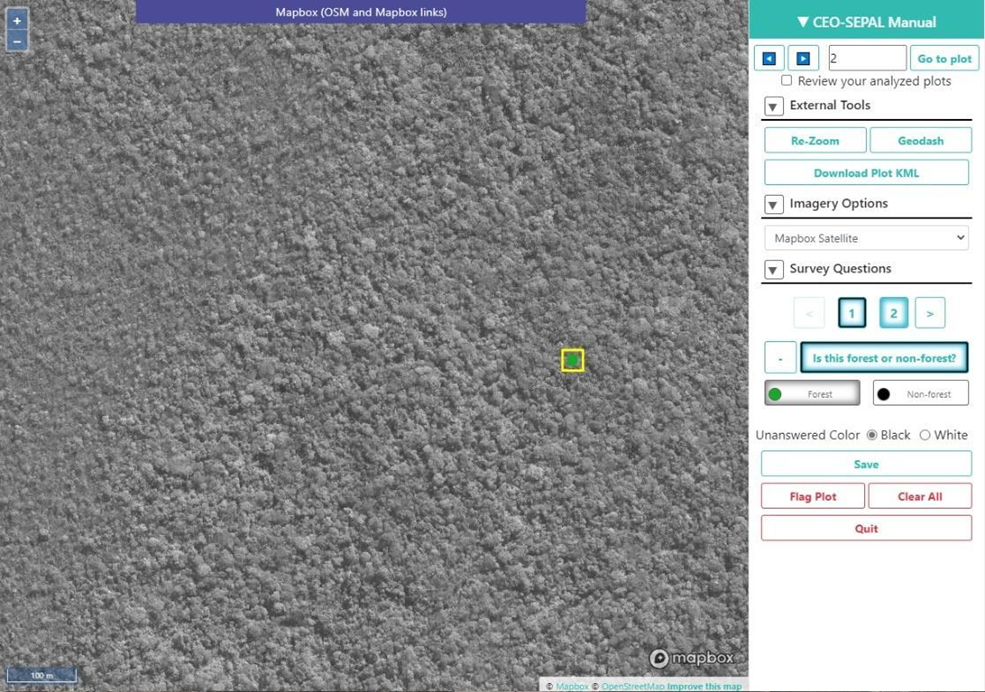
Continue answering questions until you reach the last plot. When you have finished answering all questions, go to your institution’s page.
Note
Your project name should now be green, indicating that all plots have been completed. If it is yellow, select the project name and answer the remaining questions.

Select the S next to the project. This will download your project’s sample data. Save it to your hard drive.
Data collection in CEO-SEPAL bridge#
For this example, go to the web address associated with your CEO-SEPAL bridge project (e.g. https://collect.earth/collection?projectId=18301&tokenKey=b1216bbb-9395-41f8-bc02-f898c98465bf). You must be signed out of CEO for this link to work.
Select Go to first plot. This will take you to your first plot. With the CEO-SEPAL bridge, there is only one question, CLASS, where you must assign the appropriate value to your point. The CEO-SEPAL bridge uses the names you entered during the legend labeling stage of the sample design.
Select Save to save your answers and move on to the next plot.
Continue answering questions until you reach the last plot.
Data assembly#
Data assembly is required only when you have multiple data interpreters – each working on their own project. If you have used the CEO pathway above with multiple interpreters contributing to the same project, this step is not needed.
If you have multiple interpreters, after the data collection is completed, the coordinator should create a consolidated database with all collected sample data.
The coordinator should check that all necessary metadata and sample information is archived and included in the final database.
A description of the column names from the database should be archived with the database.
A standardized naming structure is used for the compiled database and includes metadata in the folder and file name.
Each sample in the consolidated database notes the round of data collection. The database can be amended to include additional rounds of data collection. Multiple versions are recorded and explanations between versions are included in the documentation template.
Tip
In CEO, this is handled through the institution’s Project interface.
Quality management and archiving - Quality Assurance#
Quality assurance and control are fundamental in ensuring that your validation and resulting area estimates are as accurate as can be and are unbiased. This part will cover the steps of how to perform quality assurance.
For change detection maps, you will want to check for and exclude impossible transitions through logical checks. Make sure that the changes make sense (e.g. having a transition from Water <= 20% to Aquaculture may make sense, but a transition from Water <= 20% to Developed High Intensity would not).
Also be sure to document all impossible transitions. These should be included in your response design tree as well.
Conduct ongoing hot, cold and auxiliary data checks during data collection and conduct regular review meetings among all interpreters. We’ll go through each of these now.
Auxiliary data checks: use an external data source, such as externally created maps, to compare to the sample unit classification. Discrepancies between the two datasets can be flagged for rechecking. Confirmed differences between the two data sets can be documented to showcase why sample-based area estimation may give different results than other data sources.
The Copernicus Global Land Cover Layers: CGLS-LC100 collection 2, available via GEE, can be used as a comparison layer (see https://developers.google.com/earth-engine/dataset/catalog/COPERNICUS_Landcover_100m_Proba-V_Global).
Tip
Ask the following questions when comparing your map and auxiliary maps:
Where do you notice agreement between the two maps?
Where do you notice disagreement between the two maps?
What are some reasons you could attribute to the discrepancies between them?
Cold checks: sample units that are randomly selected from the data produced by interpreters. The decisions made by the interpreters are reviewed by the coordinator or group of interpreters meeting together. If the error by the interpreter reflects a systematic error in their interpretation, it is discussed directly with the interpreter and the affected sample units are corrected.
Review the table below that was a result of a cold check you conducted on the plots analysed by the interpreters.
Note
Based on some of these answers:
What can you conclude about the data?
What plots should likely be reviewed?
What other information could you gain from examining how the interpreters are performing?
Cold checks can be created in CEO by creating multiple projects with the same sample plots. Multiple interpreters can each complete one of these projects, allowing for comparison.
Interpreter
Plot 1 (Forest)
Plot 2 (Forest)
Plot 3 (Water)
Sally Ride
Non Forest Vegetation
Non Forest Vegetation
Water
Rodolfo Vela
Forest
Forest
Build up
Yuri Gagarin
Forest
Forest
Water
Hot checks: sample units that are flagged as low confidence. These marked sample units should be further reviewed by the coordinator or group of interpreters meeting together. Once reviewed, labels that are deemed to be incorrect on these sample units should be adjusted by the interpreter.
Tip
If you’re conducting this training with others, ask your colleagues about sample units that you’re unsure about.
Have your colleagues show you sample units that they are unsure about.
Discuss these sample units and make changes to the labels based on your discussion.
You must create a project using CEO to add additional questions about confidence level. If you create a project via the CEO-SEPAL interface, you will have only one question about land use/cover class.
Quality management and archiving - Quality Control#
Quality control refers to the quality of interpretation through cross-validation based on a set of samples that were assessed by two or more interpreters (see also the cold data check mentioned above). These checks can be conducted in CEO by creating multiple projects with the same sample plots. Multiple interpreters can each complete one of these projects, allowing for comparison.
Establish a reference interpretation for each of the cross-validation sample units.
Choose a reference interpretation (this should be one of the interpreter’s class assignments; it will be the basis for establishing the performance of individual interpreters).
Calculate agreement for each interpreter based on the reference interpretation. For each pair of interpreters, create a confusion matrix and include it in your project documentation.
class 1 (ref) |
class 2 (ref) |
class k (ref) |
|
|---|---|---|---|
Class 1 (interpreter) |
Counts of sample points |
Counts of sample points |
Counts of sample points |
Class 2 (interpreter) |
Counts of sample points |
Counts of sample points |
Counts of sample points |
Class k (interpreter) |
Counts of sample points |
Counts of sample points |
Counts of sample points |
For example, pretend that you and another interpreter have both collected data on a set of sample units on this Amazon land cover classification. Here are the results:
Point number |
Interpreter 1 |
Reference |
|---|---|---|
1 |
Forest |
Forest |
2 |
Forest |
Forest |
3 |
Forest |
Non-forest |
4 |
Non-forest |
Non-forest |
5 |
Non-forest |
Forest |
6 |
Forest |
Forest |
7 |
Non-forest |
Non-forest |
8 |
Non-forest |
Non-forest |
9 |
Non-forest |
Forest |
10 |
Forest |
Forest |
Calculate the confusion matrix below:
Forest (ref) |
Non-forest (ref) |
|
|---|---|---|
Forest (Interpreter) |
||
Non-Forest (Interpreter) |
Based on the confusion matrices, for each interpreter, overall agreement with the reference is to be calculated as follows:
Agreement between interpreter and the majority = Sum of counts in all the diagonal cells / Sum of all counts
The overall agreement per interpreter can be reported as below:
Interpreter |
Overall agreement |
|---|---|
Interpreter 1 |
Sum of counts in all of the diagonal cells/ Sum of all counts |
Interpreter 2 |
Sum of counts in all of the diagonal cells/ Sum of all counts |
Interpreter N |
Sum of counts in all of the diagonal cells/ Sum of all counts |
Using the table below, calculate the agreement between interpreters:
Class 1 (majority) |
Class 2 (majority) |
Class 3 (majority) |
|
|---|---|---|---|
Class 1 (Sally Ride) |
90 |
8 |
2 |
Class 2 (Sally Ride) |
6 |
84 |
10 |
Class 3 (Sally Ride) |
2 |
6 |
92 |
Class 1 (Rodolfo Vela) |
89 |
9 |
2 |
Class 2 (Rodolfo Vela) |
12 |
88 |
0 |
Class 3 (Rodolfo Vela) |
3 |
0 |
97 |
Class 1 (Yuri Gagarin) |
94 |
6 |
0 |
Class 2 (Yuri Gagarin) |
7 |
86 |
7 |
Class 3 (Yuri Gagarin) |
1 |
4 |
95 |
Interpreter |
Overall agreement |
|---|---|
Sally Ride |
Sum of counts in all of the diagonal cells/Sum of all counts |
Rodolfo Vela |
Sum of counts in all of the diagonal cells/Sum of all counts |
Yuri Gagarin |
Sum of counts in all of the diagonal cells/Sum of all counts |
Per-class agreement among interpreters should be analysed and reported as follows:
- ..csv-table
- header:
, All interpreters agreeing, One interpreter disagreeing, Two interpreters disagreeing, etc.
Class 1 (reference), Percent, Percent, Percent, Percent Class 2 (reference), Percent, Percent, Percent, Percent Class 3 (reference), Percent, Percent, Percent, Percent Total, Percent, Percent, Percent, Percent
For this example, consider the following case:
Point number |
Interpreter 1 |
Interpreter 2 |
Interpreter 3 |
Reference |
|---|---|---|---|---|
1 |
Forest |
Forest |
Forest |
Forest |
2 |
Forest |
Forest |
Non-forest |
Forest |
3 |
Forest |
Non-forest |
Non-forest |
Non-forest |
4 |
Non-forest |
Non-forest |
Non-forest |
Non-forest |
5 |
Non-forest |
Forest |
Forest |
Forest |
6 |
Forest |
Forest |
Non-forest |
Forest |
7 |
Non-forest |
Non-forest |
Non-forest |
Non-forest |
8 |
Non-forest |
Non-forest |
Non-forest |
Non-forest |
9 |
Non-forest |
Forest |
Non-forest |
Forest |
10 |
Forest |
Forest |
Forest |
Forest |
Now calculate the per-class agreement. Note that percent should be calculated by #/10 points for this example.
All interpreters agreeing |
One interpreter disagreeing |
Two interpreters disagreeing |
||
|---|---|---|---|---|
Forest (reference) |
Percent |
Percent |
Percent |
Percent |
Non-forest (reference) |
Percent |
Percent |
Percent |
Percent |
Total |
Percent |
Percent |
Percent |
Percent |
Area and uncertainty estimation#
The final step of calculating the sample-based estimates of error and area involves taking the map areas (generated in Section 4.1) and your verification data points from our data collection (Section 4.2), conducted according to the response design rules (Section 4.1), and using statistics to output the final estimates of area and uncertainty.
In Section 4.3.1, we provide an optional description of error matrices, also called confusion matrices. This provides the underlying theory for using the SEPAL Stratified estimator–Analysis tool to conduct the area and uncertainty estimation. This tool quantifies the agreement between the validation reference points and the map product, providing information on how well the class locations were predicted.
Please note that you will need to upload your collected data from CEO to SEPAL using the directions found in Section 4.1.1. If you used the CEO-SEPAL bridge, you must log out of CEO for the Import CEO Project link to work.
Objectives:
create area estimate for your classification; and
create uncertainty/error estimate for your classification.
Prerequisites:
completed verification data, or reference data (Section 4.2); and
map areas generated by your sampling design (Section 4.1).
Understanding the error matrix#
Note
This step is optional.
A common tool to quantify agreement is the error matrix (sometimes called a confusion matrix). The error matrix organizes the acquired sample data in a way that summarizes key results and aids the quantification of accuracy and area. This is a simple cross-tabulation that compares the (algorithm-assigned) map category labels to the (human-assigned) reference category labels (your validation classification). The count for each pair-wise combination are included in the blue and yellow cells in the following example.
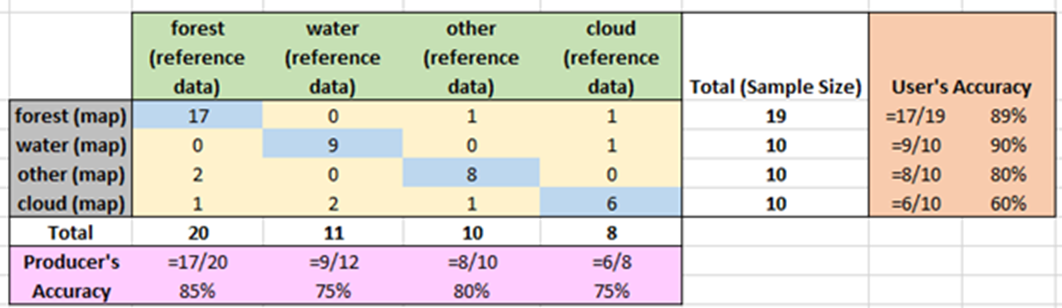
The main diagonal of the error matrix (blue cells) includes the count of the number of correct classifications.
The off-diagonal elements (yellow cells) show map classification errors.
The user’s accuracy can be quantified by dividing the number of correctly classified plots by the sum of the plots classified as the mapped class. For the forest class in the example above, this is 17 correctly identified points divided by 19 total forest plots. User’s accuracies for each class are shown in the orange cells (user’s accuracy is the complement of errors of commission – sites that are classified as forest in the map but are not actually forest).
The producer’s accuracy can be quantified by dividing the number of correctly classified plots by the sum of the plots classified as the mapped class in the validation reference sample. For the forest class in the example above, this is 17 correctly identified points divided by 20 samples that were classified as forest from the reference data. Producer’s accuracies for each class are shown in the pink cells. Producer’s accuracy is the complement of errors of omission (sites that are not classified as forest in the map that are actually forest).
For your own data, calculate an error matrix following the above guidelines.
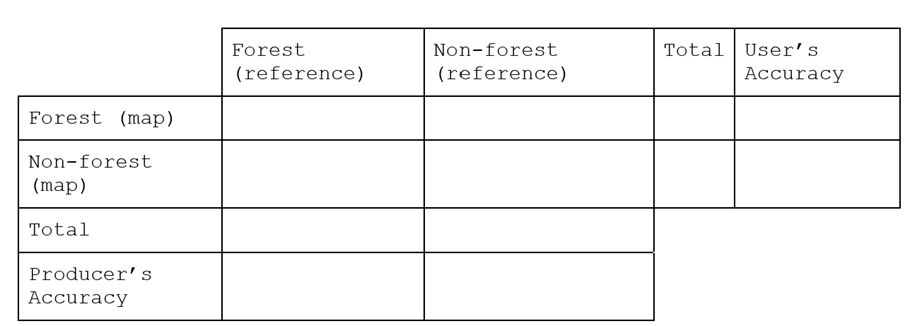
Here’s a completed example for a project using 4 classes:
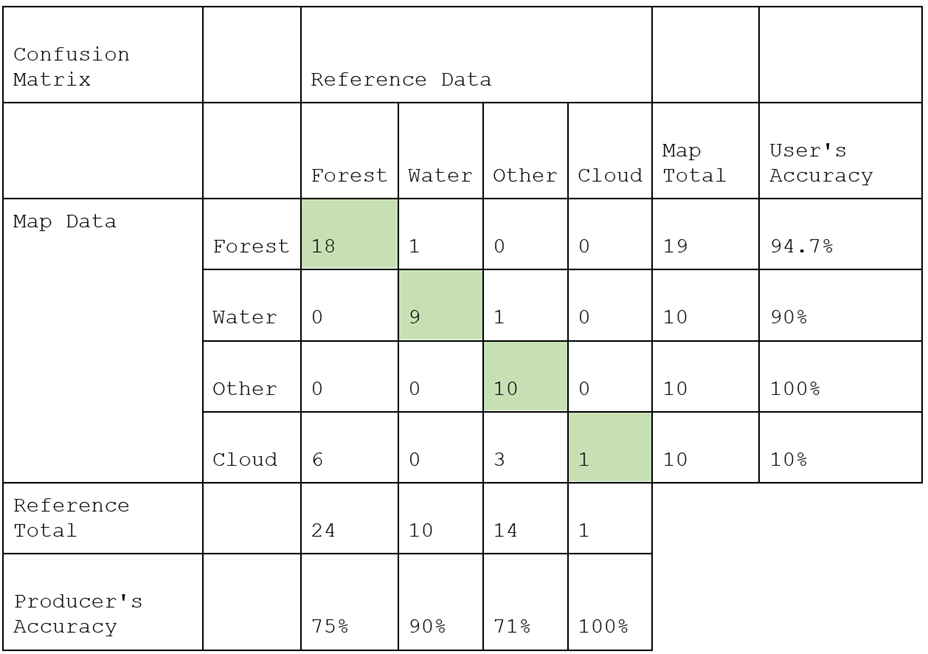
In this example, the user’s accuracy for Forest is 94.7 percent; the error of commission is 5.3 percent. The user’s accuracy for water is 90 percent, which means the error of commission is 10 percent. What this means is that according to the reference data, the map creator mapped 5.3 percent of Forest land cover in the wrong class and 10 percent of water in the wrong class. The producer’s accuracy for Forest is 75 percent, meaning the error of omission is 25 percent. The producer’s accuracy for water is 90 percent, so the error of omission is 10 percent. This means that 25 percent of the forest reference samples were mapped in the wrong land cover class, while only 10 percent of water was mapped in the wrong class. Calculate the errors of omission and commission for Other and Cloud land cover classes.
Once the error matrix is created, the area estimation becomes straightforward. Essentially, we use the frequency of these errors of omission and commission for each map class to calculate updated map areas based on our knowledge of how likely each class is to be classified as something else. We can also calculate the uncertainties for the total area of each class.
At the heart of the analysis is the implementation of an unbiased area estimator. Different estimators can be implemented to assess accuracy. In the next part, you will use stratified estimation since you have a sample stratified by the discrete map classes.
Preparing your CEO-collected data for analysis in SEPAL#
Note
This step is optional.
Open the .csv file you downloaded from CEO in Section 4.2.3. It will probably have a name like “ceo-project-name-sample-data-yyyy-mm-dd.csv”. Inspect the column data.
You should have:
A column named “PL_MAP_CLASS” that consists of numeric values. These are the classes assigned by the classification.
A column with your question about the correct map class as the column header. In this example, it is: IS THIS FOREST OR NON-FOREST.
These are the classes you assigned manually in CEO based on map imagery. This will either be numeric (1 or 2) or text (Forest and Non-forest) depending on how you set up your CEO project.
Note
If your column for the correct map class is numeric, you can directly save your .csv file and upload it to SEPAL.
If your column for the correct map class is text, you will need to either:
check that your text column matches exactly the legend labels you added during sample design (Exercise 4.1);
check that capitalization is the same (e.g. Non-forest and Non-forest not Non-forest and non-forest); or
create another column with the associated numeric value. In this case:
First, create a new column and name it COLLECTED_CLASS.
In the formula cell, type: =IF([text column letter]2=”Forest”,1,2). For this example, the text column letter is U.
Note
This will use an if statement to assign the number 1 to sample plots you assigned the value “Forest” to, and the number 2 to other plots (here, plots labeled Non-forest). If you have more than two classes, you will need to use nested if statements.
Press enter. You should now see either a 1 or a 2 populate the column. Double-check that it is the correct value.
Fill the entire column.
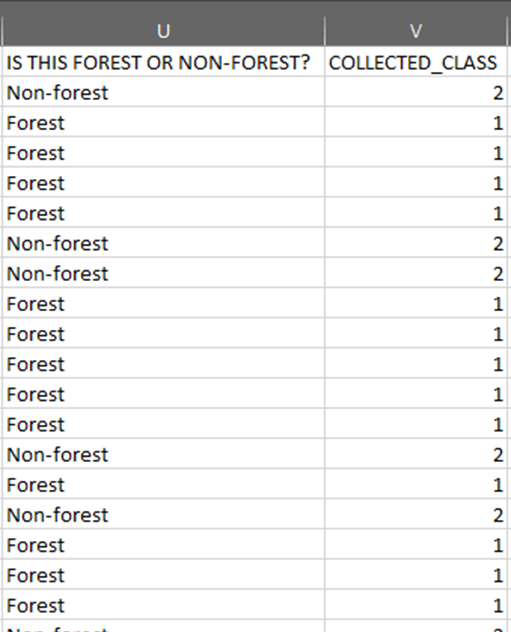
Save your .csv file and upload it to SEPAL.
Using the stratified estimator in SEPAL#
The aim of this stratified sampling design tool is to analyse results from a stratified sampling design that can be used for area estimates. The idea is to combine a map (used as a stratification of the landscape of interest) with a visual map interpretation of samples to produce an area estimation.
The concept is derived from map accuracy assessment principles: characterized frequency of errors (omission and commission) for each map class may be used to compute area estimates and also to estimate the uncertainties (confidence intervals) for the areas for each class.
First, open the Stratified Area Estimator-Analysis tool. In the SEPAL Apps window, select Stratified Area Estimator - Analysis. This tool is very similar to the Design tool that you used to create your stratified sample.
You will land on the Introduction page which allows you to choose your language and provides background information on the tool. Note that Reference and Documents are in the same place as the Design tool. The pages that contain the necessary steps for the workflow are on the left side of the screen and need to be completed sequentially.
Select the Inputs page on the left side of the screen. You will see two data requirements under the Select input files section.
Reference Data: This refers to the table that you classified and exported in the previous section. It will contain a column that identifies the map output class for each point as well as a column for the value from the image interpreter (validation classification).
For projects completed in CEO: Select the Reference data button and navigate to the .csv file you downloaded from CEO and then uploaded to SEPAL in Section 4.3.2.
For projects completed in the CEO-SEPAL bridge: - Check that you are signed out of the CEO website. - Paste the URL from your CEO-SEPAL bridge project into the field marked CEO URL. You can also click the Paste CEO URL from clipboard button. - Select
Import CEO project. This will populate the input file for the reference data as well as the column names.
Area data: This is a .csv file that was automatically created during the Stratified Area Estimator – Design workflow. It contains area values for each mapped land cover class.
Select the Area data button.
Open the sae_design_AmazonClassification folder, or the folder labeled
sae_design_your-name-here(if you did not call your classification AmazonClassification). As a reminder, if you exported your classification to the SEPAL workspace, the file will be in your SEPAL Downloads folder. (downloads > classification folder > sae_design_AmazonClassification). Within this folder, select area_rast.csv (see image below).
Next, you will need to adjust some parameters so that the tool recognizes the column names for your reference data and area data that contain the necessary information for your accuracy assessment. You should now see a populated Required input pane on the right side of the screen.
Choose the column with the reference data information.
Note
For projects completed in CEO: This will either be your question name or the new column name you created in Part 2 above. Here, it is COLLECTED_CLASS (following the directions in Section 4.3.2).
For projects completed in CEO-SEPAL: ref_code
Choose the column with the map data information.
Note
For projects completed in CEO: PL_MAP_CLASS
For projects completed in CEO-SEPAL: map_code
Choose the map area column from the area file—map_area.
Choose the class column from the area file—map_code or map_edited_class. The map_edited_class has the names you entered manually during the design phase, while the map_code has the numeric class codes.
Note
For projects completed in CEO: Use map_code if you have a column in your reference data. If you use map_edited_class, you must make sure that capitalization is consistent.
For projects completed in CEO-SEPAL, use map_code.
You can add a Display data column to enable validation on the fly. You can choose any column from your CEO or CEO-SEPAL project. We recommend either your map class (e.g. PL_MAP_CLASS) or your reference data class (e.g. question name column). This example uses a CEO project.

Once you have set these input parameters, select Check on the left side of the window. This page will simply plot your samples on a world map. Fix the locations of your plots by specifying the correct columns to use as the X and Y coordinates in the map. Select the dropdown menus and choose the appropriate coordinate columns for the X and Y coordinates. The X coordinate should be LON; the Y coordinate should be LAT.
Next, select the Results page on the left side of the screen.
The Results page will display a few different accuracy statistics, including a Confusion Matrix, Area Estimates, and a Graph of area estimates with confidence intervals. The Confusion Matrix enables you to assess the agreement of the map and validation datasets.
The rows represent your assignments, while the columns represent the map classifiers. The diagonal represents the number of samples that are in agreement, while the off-diagonal cells represent points that were not mapped correctly (or potentially not interpreted correctly).
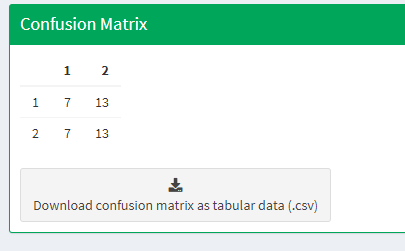
Typically, you would have to create the confusion table yourself and calculate the accuracies; however, the SAE-Analysis tool does this for you.
See also
If you completed Section 4.3.1, how does the SAE-Analysis tool’s calculations compare with your own?
You can download the confusion matrix as tabular data (a .csv file) using the button.
Under Area estimates, the table shows you the area estimates, as well as producer’s and user’s accuracies – all of which were calculated from the error matrix and the class areas (sample weights) from the map product you are assessing.
Estimations are broken up into simple and stratified estimates, each of which has its own confidence interval. In this exercise we collected validation data using a stratified sample, so the values we need to use are the stratified random values. Note that all area estimates are in map units. You can change your desired confidence interval by using the slider at the top of the pane. You can Download area estimates as tabular data (a .csv file) using the button.
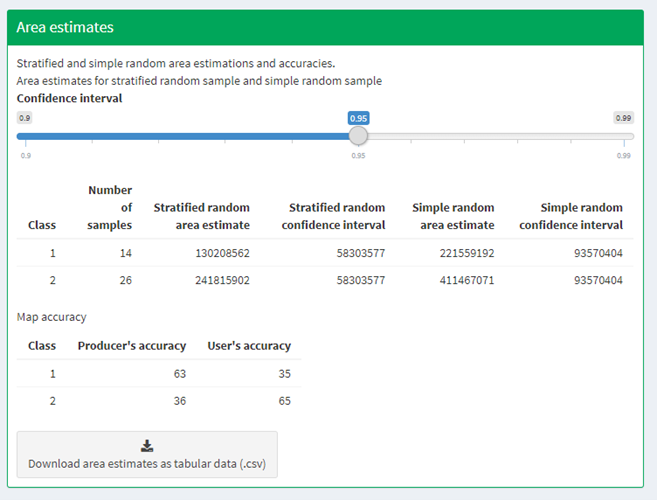
The Graph plots area estimates based on: map pixel count, stratified random sample, simple random sample, unbiased stratified random and direct estimate stratified random.
In this exercise, we collected validation data using a stratified sample, so the values we need to use are the stratified random values. Need to define unbiased stratified random and direct estimate stratified random.
Note
The map pixel count value differs from these stratified random sample estimates. This shows how using a map pixel count is a poor estimation of actual area.
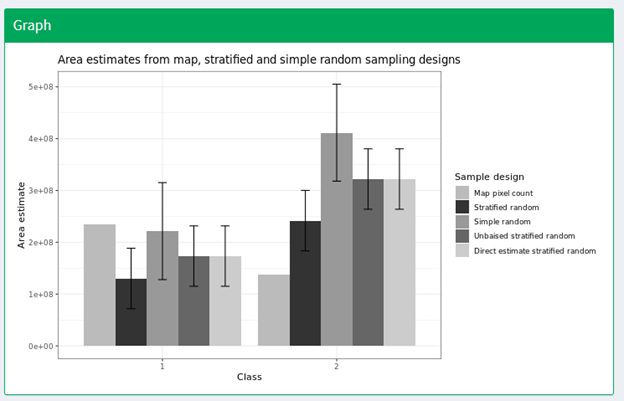
Documentation and archiving#
Documentation of your area estimate and archiving this information for future reference are critical in order to replicate your estimation process. Examples where you would want to repeat your analysis include different areas (states, provinces, ecological regions) or time periods (months, years).
We have built in documentation steps into other modules of this guide; however here we bring this information together. We discuss key documentation steps, including logging decision points (Section 5.1), Reporting (Section 5.2), Commenting in code (Section 5.3), and Version control (Section 5.4), as well as Archiving steps (Section 5.5).
This module should take approximately 1 hour to read. The time taken to complete this module for your specific situation will vary depending on the size and scope of your project.
Logging decision points#
Logging decision points is a critical part of documenting your area estimation process and being able to recreate your estimation process.
A decision point is anywhere where you make a decision about your project that can change the outcome (e.g. “We decided that pixels with over 75 percent tree cover should be classified as Forest cover” is a decision point).
In the previous modules, we have suggested that you document these types of decision points as you go along. This includes:
-
logging your land use decision tree (Section 2.1);
logging your land use classification definitions (Section 2.1); and
settings used for classification, along with any refinements (Section 2.4).
-
logging two-date change detection decisions, including what classes can change and imagery and processes used in the classification (Section 3.1).
-
stratification choices (Section 4.1); and
data collection procedures (Section 4.2).
You may also choose to follow your organization’s SOPs (e.g. https://drive.google.com/file/d/1u4sXx6Y8qPKvbIYJFide5EI6L_ygpS5p/view?usp=sharing).
Reporting#
Writing a report summarizing your findings is a critical part of your area estimation. If you are conducting an area estimation for internal use, this report will provide you with a blueprint for future estimations. If you are conducting an area estimation for another organization, this report will convey your results and the quality of your analysis.
Here we provide a rough outline of what you should include in your reporting.
In your report, you should include:
an introduction, describing why the project was completed and any goals of the project
your project’s methods (how your project was completed), including:
all tools used in your analysis
all decision points (Section 5.1)
any other information needed to recreate your project
your project results:
your area estimation (Section 4.3).
the error associated with your classification (Section 4.3)
a comparison of any self-checks (one interpreter) and cross-checks (between interpreters) with the main sets of plots.
any actions or next steps arising from your analysis.
Writing your report will take time and attention. Documenting your steps along the way, as discussed in Modules 1-4 and Exercise 5.1 will help you write your report more efficiently.
Attention
Always follow your organization’s reporting guidelines (e.g. if your estimation is developed to support a NFMS, you will need to comply with UN reporting standards).
FAO’s SOP requires reports to include at least the following information about the data collection process:
a brief narrative on the modalities for data collection;
the interpreters, their contact information, institutions and roles;
overview of sample unit allocation to interpreters and any subsequent revisions made to the allocation;
a summary of the training conducted that details the topics covered;
a list of attendees for the training and their attendance record;
challenges and limitations during the data collection;
potential sources of bias during the data collection;
impossible transitions excluded from data collection;
the results of the assessment of interpretation quality; and
external appraisal of interpretation quality contact information and narrative report from the appraiser.
Commenting in scripts#
While none of the steps involved in this manual require writing code, more complex classification projects may use programming environments such as GEE. This exercise discusses best practices for commenting your code if you use tools such as GEE.
Leaving comments in your code can be a helpful way to describe information of what a particular function does, leave warnings or considerations to other programmers (including your future self!), provide key information on licensing, or save information on what you still want to complete while coding. In this section, we will briefly demonstrate both good and bad commenting techniques.
When commenting your code, you should take into account your target audience. Is your code going to be used for a workshop? Will it be read by other scientists or programmers? Will you lose access to it after submitting it to a publication or project partner? Answering these questions will help you determine what approach to take when commenting.
Many of these tips are derived from the suggestions laid out in Robert C. Martins’ book Clean Code, which would be a good reference if you would like to learn more about coding cleanly and commenting:
Keep comments short. Keeping your comments short is helpful to both the writer of the comment and the reader. Having multiple long comments in your code can lead to readers skipping over them and thus making them inefficient. Long comments can start to clutter your code.
It is best to use comments sparingly; when possible, rename variables or use functions to reflect what you would like to have commented. Comments can quickly become outdated and are less of a priority to update. Comments are a representation of what your code does, but can sometimes be misleading.
Using comments to add some informative content or explain the intent behind your code, but don’t be redundant. Informative comments are little snippets of information that aid in reading through your code. A comment explaining your intent can be useful where the processing you have done is slightly complicated to read through.
Don’t leave in commented out code. Leaving in commented out code quickly becomes confusing. Is the commented out code something new that is to be implemented? Is it something that was broken and the other code fixed? Should it be uncommented to provide a different result? It is best to use a form of version control so you can safely delete these lines and go back to them if you need to later.
Try to not be redundant with comments. Comments that simply reiterate what the code is doing often are not helpful and will add to clutter. Use comments to clarify what the code is doing. This is nice for when you are using code in a workshop, or perhaps in a final version that is released with a publication that will not be changed later.
Do be careful as just like with other comments, errors in them are just as bad as in your code!
Here are three examples of comment types:
Comments that clarify:
////////////////////////////////////////////////////////
// User defined variables ///
////////////////////////////////////////////////////////
// Main variables for defining region of interest,
// start and end period, and sensors to include
// Available sensors are : Landsat, Sentinel2, Sentinel1,
var sensor = 'Landsat';
Comments that are informative:
// returns most recent image with time series of images as property
Return ee.Image(latestImagery)
Comments that describe intent:
// This is the best way I found to add images to the target image as a property
var processMetaData = imageCollection.map(function f (img){
var imageDate = img.get('system:time_start')
var previousImages = otherImageCollection.filterDate(imageDate.advance(-1,'month') , imageDate).filterBounds(img.geometry().bounds())
return img.set('images', previousImages.toList())
});
And here is an example where comments (A) can be replaced by variables (B).
/////////////////////////////////////////
// example A: using comments //
/////////////////////////////////////////
// Did the user pass in a year range that is within the valid range for
// the selected satellite?
if(dateInputBox.getValue().includes(sensorDateRangeDict[sensorInputBox.getValue()]){
// run analysis for date range
var results = myAnalysis(dateInputBox.getValue(),sensorInputBox.getValue())
}
///////////////////////////////////////////////
// example B: using variable names //
///////////////////////////////////////////////
var selectedDateRange = dateInputBox.getValue()
var selectedSensor = sensorInputBox.getValue()
var selectedSensorDateRange = sensorDateRangeDict[selectedSensor]
if( selectedDateRange.includes(selectedSensorDateRange)) {
var results = myAnalysis(selectedDateRange, selectedSensor)
}
In this example above, you can see that you write roughly the same number of lines of code with and without comments. However, by adding descriptive variable names, the code itself becomes simpler to understand.
Finally, note that reading the actual code will always be truer than reading the comments. In the first example, it poses the question: “Did the user pass in a year range that is within the valid range for the selected satellite?” But what if you choose to include aerial imagery or UAV data sources at some point? Chances are, you won’t feel compelled to go back and update your comment.
Transparent coding: GitHub and saving GEE scripts#
In addition to commenting your code so that future users can understand what is being done, saving your code is another important part of project documentation. As in Section 5.3, this exercise is only relevant if you have implemented code in your area estimation, such as through Python or GEE.
In this exercise we will touch upon how to be transparent with your code and save your code. Any time you are writing a script or some code, it is probably a good idea to have a version control system in place so you can track your changes and have a backup in case a mistake happens to your code. We discuss this in two contexts: Git for local code and GEE’s approach to version control.
Version Control and Git#
Version control is “a system that records changes to a file or set of files over time so that you can recall specific versions later” (Git, 2020; see https://git-scm.com/book/en/v2/Getting-Started-About-Version-Control). Version control can be applied to many different file types, but is most commonly used with text-based code, such as Python and R scripts.
Note
The following explanation is adapted from the Software Carpentry Git lesson.
We’ll start by exploring how version control can be used to keep track of what one person did and when.
We’ve all been in this situation before: it seems ridiculous to have multiple, nearly identical versions of the same document. Some word processors let us deal with this a little better, such as Microsoft Word’s Track Changes, Google Docs’ Version History, or LibreOffice’s Recording and Displaying Changes.
Version control systems start with a base version of the document and then record changes you make each step of the way. You can think of it as a recording of your progress: you can rewind to start at the base document and play back each change you made, eventually arriving at your most recent version.

Once you think of changes as separate from the document itself, you can then think about “playing back” different sets of changes on the base document, ultimately resulting in different versions of that document (e.g. two users can make independent sets of changes on the same document).

A version control system is a tool that keeps track of these changes for us, effectively creating different versions of our files. It allows us to decide which changes will be made to the next version (each record of these changes is called a commit, and keeps useful metadata about them. The complete history of commits for a particular project and their metadata make up a repository. Repositories can be kept in sync across different computers, facilitating collaboration among different people.
Of version control systems, Git (and implementation GitHub that includes a GUI Desktop version) is perhaps the most widely used. Here we provide a very basic overview of Git and links to additional resources.
Git is a popular free and open-source software for a distributed version control system and is the basis of GitHub. With a GitHub account, you can create repositories to hold your code and track the changes you make to it as you develop it. GitHub stores all your code, which means that even if something happens to your computer, your code will be saved.
This is also a great way to share or collaborate on code. You can easily send a link to your repository to whomever you want, and you could have other scientists working on one portion of the code on their home computer while you do as well.
See also
If you would like to learn more about Git or version control, you can work through the Software Carpentry workshop at your own pace here: http://swcarpentry.GitHub.io/git-novice.
You can work through how to set up a Git repository system for yourself or your organization (unpaid but must run locally or on your own servers).
Note
Information on Git can be found here: https://git-scm.com.
Information on GitHub, including how to sign up, can be found here: github (GitHub has free and paid service tiers).
Tip
With https://zenodo.org and GitHub together, you can create DOI numbers for versions of your code for publication.
GEE version control#
GEE has implemented version control and version history for all scripts and repositories written on the platform. To access the version control, Select the history icon next to a script in order to compare or revert it to an older version.
Detailed information can be found under “Development Environments: Earth Engine Code Editor” here: https://developers.google.com/earth-engine/guides/playground
Data archiving and creating metadata#
Finally, we will discuss the information needed for proper data archiving, which overlaps significantly with creating metadata for your area estimation. Metadata is a set of data that provides information about other data, such as your classification and area estimation data.
Data archiving#
For data archiving, the following information needs to be compiled:
a database of the sample data collected by the interpreters, including:
the geographical coordinates in defined coordinates or projection system;
the unique identification code for each sample unit; and
the interpretation of all sample units including the previous interpretation(s) of the sample unit in the case this was revised or corrected.
the interpretation of sample units conducted by the coordinator
metadata regarding the interpreter that collected the sample data, when the data was collected, and which data sources were used.
Think about the work you did in completing Module 1, Module 2, Module 3 and Module 4. What other data do you think should be archived? What would be helpful to your colleagues or yourself in the future looking to replicate your work?
You should store the data collection report, your data tables, any metadata, etc. in a standard format. When naming files, you should follow a naming convention, such as Data collection_data_date[year/month/day]_version number (FAO SOP). When writing your documentation report, you should include links to your data storage locations.
Creating metadata#
This worksheet is designed to assist you in becoming more efficient and informed about documenting and archiving information related to the planning, preparation and management of remote sensing datasets and analysis, such as analyses conducted for forest inventory monitoring (e.g. REDD+ activities).
Documentation and archiving remote sensing analysis methods ensures that there is transparency and makes it easier to replicate or improve methods as programs increase in complexity and robustness. For more information on the good practice recommendations for documentation, archiving and reporting, please refer to the 2006 IPCC Guidelines (Volume 1, Chapter 6, Section 11).
Below, we have provided you with headings and some questions for each step in the metadata creation process, including where you should provide information about your workflow in order to ensure transparency about your data and processing steps, and to comply with best practices. The information you provide below should be sufficient and clear enough so that someone else can understand how the analysis was conducted and would be able to replicate it.
When completing this exercise, think about the work you have completed in the first four modules. When you conduct your own classification and area estimation processes in the future, take the time to customize and add additional sections to this document. This exercise is designed to get you started in this practice and moving down the right path.
Preparing and Downloading Cloud-free Composite Using GEE |
|
|---|---|
Data used |
|
Time frame for composite |
|
Software used |
|
Pre-processing methods |
|
Methods for cloud removal |
|
Assess RS results |
|
Assumptions (Note: Need to archive outputs before proceeding with analysis) |
Creating Band Ratios, Indices and Image Transformation for use in Classification and Change Detection Analysis |
|
|---|---|
Software used |
|
Description of indices |
|
Assess RS results |
|
Assumptions (Note: Need to archive outputs before proceeding with analysis) |
Image Classification Scheme |
|
|---|---|
Document Clear definitions for classes or categories (i.e. land-use categories defined by the IPCC as: Forest Land, Cropland, Grassland, Wetlands, Settlements and Other Land) |
|
Have you identified any categories as “Key Categories”? How is the analysis different? Please refer to Volume 1, Chapter 4 of the 2006 IPCC Guidelines on what defines a “Key Category”. |
|
Assess RS results |
|
Assumptions (Note: Need to archive outputs before proceeding with analysis) |
Collect Reference Data |
|
|---|---|
What type of reference data are you using? |
|
What is your sampling scheme and what is the logic for its design? |
|
Assess RS results |
|
Assumptions (Note: Need to archive outputs before proceeding with analysis) |
Perform Land Cover Classification or Land Cover Change Analysis |
|
|---|---|
Software |
|
Analysis technique |
|
Assess RS results |
|
Assumptions (Note: Need to archive outputs before proceeding with analysis) |
Perform Accuracy Assessment |
|
|---|---|
Sampling approach |
|
Analysis technique |
|
Assess results |
|
Assumptions (Note: Need to archive outputs before proceeding with analysis) |
Conclusion#
Note
Congratulations! You have completed the SEPAL-CEO Area Estimation recipe!
Now you know:
how to perform an accuracy assessment and generate area estimates in SEPAL;
how to conduct a two-date change detection classification in SEPAL;
how to create a stratified random sampling design for your map and a project (CEO or CEO-SEPAL) to collect reference data;
how to create a Landsat mosaic using the many customizable parameters in SEPAL;
how to collect training data in SEPAL’s classification interface;
how to produce map classifications in SEPAL;
how to assess important quality assurance metrics for your project;
how to log key decision points for your project;
how to comment code;
how to use version control options for your project; and
how to report your area estimation project.